


Meta published new technical details on its Meta Training and Inference Accelerator (MTIA) program, outlining a rapid multi-generation roadmap for custom AI processors designed to power machine learning workloads across its global infrastructure.
In a blog post titled “Four MTIA Chips in Two Years: Scaling AI Experiences for Billions,” Meta said it has already deployed hundreds of thousands of MTIA chips in production and is accelerating development across multiple new generations of accelerators optimized for ranking, recommendation, and generative AI workloads. The MTIA family is being developed in partnership with Broadcom and is designed to complement Meta’s broader portfolio of AI infrastructure technologies.
The company said its MTIA strategy focuses on delivering custom hardware optimized for the specific workloads that dominate its infrastructure. Early generations focused primarily on ranking and recommendation inference, while newer chips target generative AI inference and training workloads that are rapidly growing across Meta’s platforms.
Key Points
• Meta details roadmap for MTIA custom AI accelerators
• MTIA chips developed in partnership with Broadcom
• Hundreds of thousands of MTIA devices already deployed in production
• New chip generations target GenAI inference and training workloads
• Modular chiplet architecture enables rapid development cadence
• MTIA software stack built around PyTorch and open ecosystems
“Our MTIA strategy focuses on delivering the right hardware for the right workload at the right time,” Meta wrote in its engineering blog. “By iterating quickly across chip generations and tightly integrating hardware and software design, we can continuously optimize our infrastructure for the AI workloads that power experiences for billions of people.”
| MTIA Generation | Primary Workload | Key Architectural Features | Deployment Status |
|---|---|---|---|
| MTIA 100 / MTIA 200 | Ranking & Recommendation inference | First-generation custom accelerators optimized for Meta’s internal AI workloads | Deployed in production |
| MTIA 300 | Ranking & Recommendation training | Built-in NIC chiplets, message engines for collective communication, near-memory reduction compute | Production deployment |
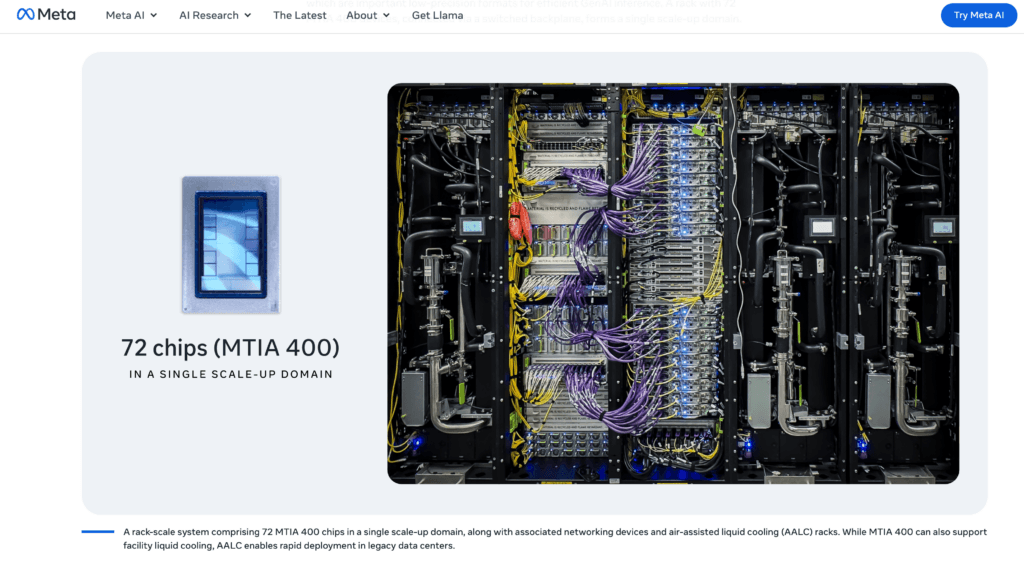
| MTIA 400 | GenAI + R&R workloads | Dual compute chiplets, enhanced low-precision formats (MX8/MX4), 72-accelerator rack-scale scale-up domain | Testing / deployment phase |
| MTIA 450 | GenAI inference | 2× HBM bandwidth vs MTIA 400, hardware acceleration for attention and FFN operations, new low-precision data types | Mass deployment planned 2027 |
| MTIA 500 | Advanced GenAI inference | 50% higher HBM bandwidth, up to 80% more HBM capacity, modular 2×2 compute chiplet architecture | Scheduled for deployment 2027 |
https://ai.meta.com/blog/meta-mtia-scale-ai-chips-for-billions
🌐 Analysis
Meta’s MTIA program reflects a growing trend among hyperscale cloud providers toward vertically integrated AI infrastructure stacks. Instead of relying solely on merchant GPUs, companies such as Meta, Google, Amazon, and Microsoft are designing custom accelerators optimized for their own machine learning workloads.
Meta’s design strategy differs from some competitors by focusing heavily on inference workloads first. Recommendation systems and ranking models represent the dominant compute workload across Meta’s services, and optimizing hardware specifically for these tasks can deliver significant efficiency gains.
The MTIA architecture also emphasizes modular chiplet design. Each accelerator generation is built from reusable chiplets for compute, networking, and I/O. This allows Meta to introduce improvements to individual components without redesigning the entire chip. The company says this approach allows it to release new accelerator generations roughly every six months.
Networking and memory bandwidth are central design considerations for the MTIA family. For example, MTIA 400 uses a scale-up domain connecting 72 accelerators within a rack, while later chips increase high-bandwidth memory capacity and bandwidth to support generative AI inference workloads.
Meta also highlighted a tightly integrated software stack built around PyTorch, TorchInductor, Triton, MLIR, and LLVM. The system allows models to run across both GPUs and MTIA accelerators using the same framework tools, enabling developers to migrate workloads without rewriting models.
According to Meta, the rapid development cadence of the MTIA family has allowed the company to increase HBM bandwidth by roughly 4.5× and compute performance by approximately 25× across successive generations in less than two years.
| MTIA Architecture Layer | Key Components | Role in AI Infrastructure |
|---|---|---|
| Compute Chiplets | Processing Element grid with RISC-V vector cores, dot-product engines, reduction engines, DMA controllers | Executes matrix operations and neural network compute workloads used in ranking, recommendation, and generative AI models |
| Memory Subsystem | High-Bandwidth Memory (HBM) stacks | Provides extremely high bandwidth needed for large model inference and training workloads |
| Networking Chiplets | Dedicated network interfaces and message engines | Enables high-speed communication between accelerators and supports distributed AI workloads |
| Scale-Up Infrastructure | Rack-level systems connecting up to 72 MTIA devices | Creates large accelerator domains for AI training and inference workloads |
| Communication Software | Hoot Collective Communications Library (HCCL) | Handles distributed training communication and collective operations across accelerators |
| Software Frameworks | PyTorch, Triton, MLIR, LLVM, TorchInductor | Allows AI models to run on MTIA using familiar machine learning development tools |
| Deployment Infrastructure | OCP-aligned servers, racks, and networking systems | Allows MTIA accelerators to integrate directly into Meta’s hyperscale data centers |