At the Optica Executive Forum in Los Angeles, Meta’s Drew Alduino laid out the sheer scale and complexity of building AI infrastructure at hyperscale, emphasizing that while optical technologies like co-packaged optics (CPO) and linear pluggable optics (LPO) offer compelling power advantages, the real gating factors are reliability, serviceability, and total cost of ownership. Meta, he stressed, is fundamentally an end-user operating at unprecedented scale, now serving 3.4 billion daily active users across its platforms, with AI deeply embedded across recommendation engines, feeds, and emerging agentic workflows. Supporting that demand requires infrastructure on a scale measured not in data centers, but in “city-sized” AI campuses.
Meta is aggressively expanding its AI footprint, with plans for multi-gigawatt compute deployments and over 1.3 million GPUs in 2025 alone. Capital expenditures are rising sharply, exceeding $115 billion in 2026, up from $70 billion in 2025 and $35 billion in 2024, reflecting what Alduino described as a broader industry trajectory toward more than half a trillion dollars in AI infrastructure investment. Projects like the Hyperion data center in Louisiana—designed to scale beyond 5GW—illustrate how hyperscale operators are evolving toward “AI factories,” requiring tight integration across compute, networking, power, and cooling. These deployments are supported by a growing ecosystem of partners, including NVIDIA, AMD, and Corning, alongside Meta’s own MTIA silicon initiatives.
Within these environments, networking is under increasing pressure—not just to scale bandwidth, but to do so efficiently. While GPUs dominate power consumption, Alduino noted that even small percentage gains in network efficiency translate into significant absolute savings at multi-gigawatt scale. This has driven interest in integrated optics approaches such as LPO and CPO, which reduce power by minimizing retiming and shortening electrical paths. However, he cautioned that the industry has largely answered the question of whether these technologies can work; the more important question now is whether they should be deployed, given trade-offs in reliability, observability, and serviceability.
A central theme of the presentation was the growing importance of RAS—reliability, availability, and serviceability—as the key decision framework for next-generation interconnects. Alduino emphasized that failures in tightly integrated optical systems can have outsized impact, potentially taking down large portions of a cluster and requiring time-consuming repairs. In hyperscale environments, this translates directly into overprovisioning requirements and higher effective costs. The shift from pluggable optics to integrated approaches therefore requires a fundamentally different evaluation of system-level behavior, not just component-level performance.
Meta’s current GPU infrastructure highlights the physical limits of scale-up architectures based on copper. Today’s GB300-class racks already require complex electrical backplanes with thousands of differential pairs, and expanding beyond 144 accelerators per domain pushes against the practical limits of copper reach, power, and density. While copper remains the “gold standard” due to its cost efficiency and maturity, Alduino argued that future scale-up domains—potentially exceeding 256 accelerators—will likely require optical interconnects to overcome these constraints. Optical backplanes and emerging standards such as OCI are seen as key enablers, provided the industry can deliver a robust, interoperable ecosystem.
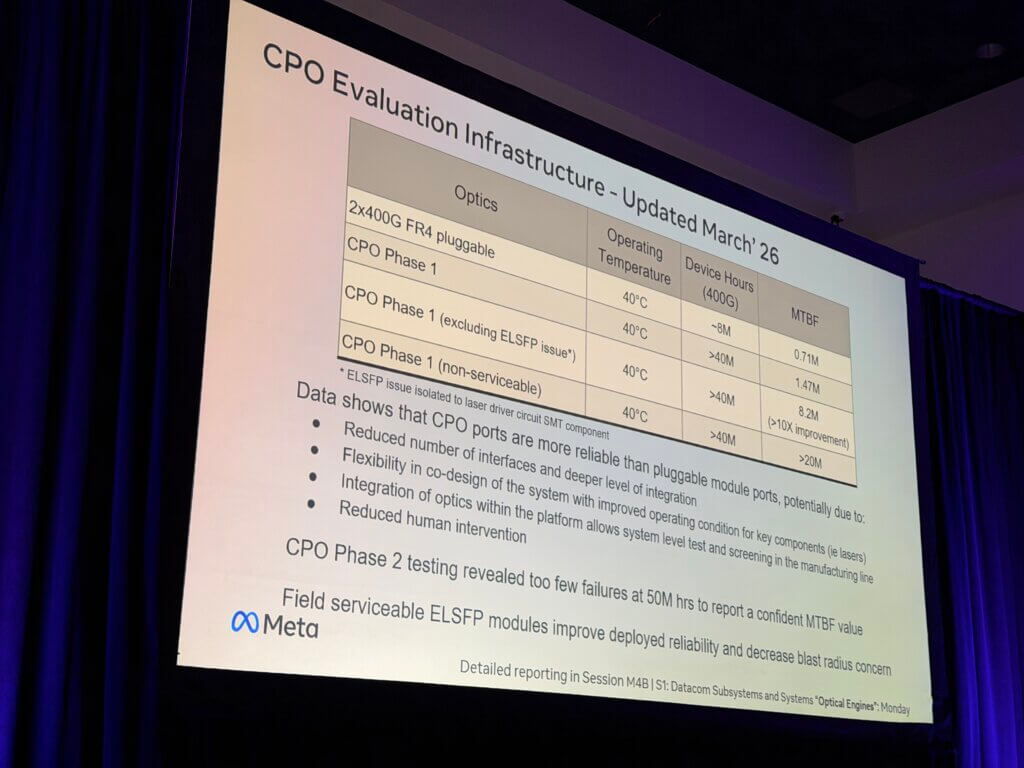
Meta has been actively evaluating CPO reliability at scale, deploying large test clusters to gather meaningful operational data. The company reported more than 50 million device-hours of testing on Phase 2 CPO systems, building on earlier Phase 1 results. Initial findings indicate that CPO architectures can achieve higher reliability than traditional pluggable modules, driven by reduced component counts and tighter integration. However, Alduino noted that the data is still evolving, and longer-term results are needed to establish confident mean time between failure (MTBF) benchmarks. Importantly, Meta is also exploring field-serviceable designs to mitigate the operational risks associated with highly integrated optics.
Ultimately, Alduino framed the industry’s challenge as a transition from electrical to optical scale-up domains, driven by exponential growth in AI cluster size. While copper will remain foundational in the near term, its limitations are becoming increasingly apparent. Optical interconnects—combined with standardization efforts like OCI—offer a path forward, but only if the ecosystem can address the full RAS equation at hyperscale. As Alduino concluded, the technical feasibility of optical scale-up is no longer the primary barrier; the challenge now is delivering systems that are reliable, serviceable, and economically viable at the scale required for next-generation AI infrastructure.
Key Points
- Meta serves 3.4B daily active users; AI is embedded across all applications
- AI infrastructure scaling toward multi-gigawatt deployments and “AI factory” campuses
- CapEx trajectory: >$115B (2026), >$70B (2025), >$35B (2024)
- 1.3M GPUs expected in 2025; industry-wide AI infra spend approaching $500B+
- Hyperion data center in Louisiana designed to exceed 5GW capacity
- Networking power is a small percentage, but significant at hyperscale (multi-GW impact)
- LPO and CPO reduce power but introduce trade-offs in RAS and serviceability
- Copper backplanes remain cost and reliability baseline but face scaling limits
- Future scale-up domains (>256 accelerators) likely require optical interconnects
- CPO testing: >50M device-hours; early data shows improved reliability vs pluggables
- OCI emerging as key standard for interoperable optical scale-up ecosystems
“We’ve largely answered ‘can we build these systems.’ The real question now is ‘should we’—because every gain in power efficiency comes with real costs in reliability, availability, and serviceability at hyperscale.”