PIC Summit USA | Sunnyvale, California
Nvidia’s Ashkan Seyedi, Director of Networking at NVIDIA, used his PIC Summit keynote to make a pointed argument for the interconnect community: as inference and reasoning models drive more data movement inside AI systems, operators increasingly want interconnect to become “transparent”—engineered to be power-efficient, manufacturable at hyperscale, and operationally predictable—so it fades into the background like plumbing until it fails.
Seyedi framed the moment as a rapid transition from “pluggables as default” to a world where co-packaged optics (CPO) and “optics-in-the-box” architectures become necessary to keep pace with GPU systems that have evolved from “cards to boxes to racks and rows,” and now to “infrastructure” spanning multiple buildings and even multiple cities. In that expanding construct, he argued, those working on interconnect will remain “gainfully employed,” because the AI value chain increasingly depends on moving data—especially as model architectures shift toward mixtures of experts (MoE), agentic workflows, and higher inference-time compute.

A key workload driver in his talk was the KV cache. Seyedi’s logic was direct: if KV cache is sitting idle, no one is using it; to monetize inference you have to move it. MoE, he said, only intensifies this by increasing “internal thinking” (token generation) and therefore memory traffic. The implication for system architects is that AI systems will not converge on a single “one-size-fits-all” network design. Instead, they will be tuned across a matrix of knobs—coherence domains, GPU counts per expert, placement, and where state is stored or offloaded—creating demand for more flexible optical integration and packaging choices.
He tied interconnect requirements to Nvidia’s current system trajectory and deployment model. Seyedi highlighted the move toward large, factory-like assemblies—liquid-cooled, pre-integrated, and designed for rapid manufacturing throughput—because deployment can no longer be gated by “a missing spring or a missing connector.” The operational objective, as he described it, is shipping infrastructure at industrial cadence: pre-assembled modules that arrive at a contract manufacturer and “snap together like Legos,” avoiding manual touch labor and clean-room-style interventions that would throttle volume.
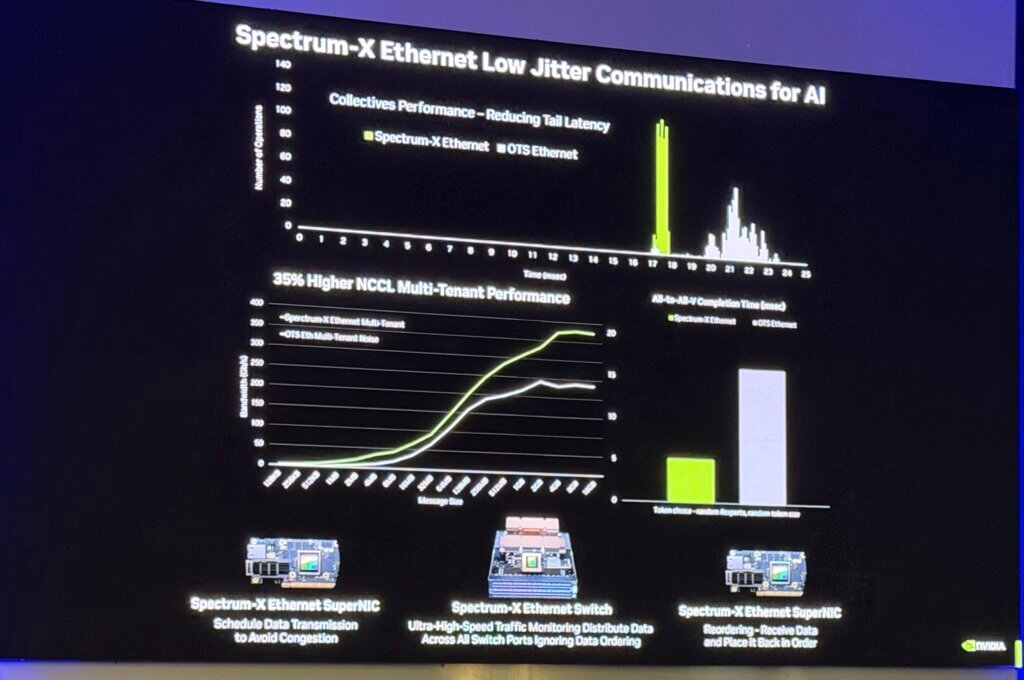
On the networking side, Seyedi emphasized minimum tail latency and predictability—reducing jitter and contention rather than trying to recover from them after they appear. The “best problem to solve is the one you don’t get into,” he said, implying that traffic engineering, scheduling, and architectural segmentation can remove entire classes of tail-latency penalties. He linked this to familiar HPC lineage—essentially the scatter-gather problem reappearing in AI clothing—where synchronized workloads amplify the cost of long tails and unpredictable completion times.
Seyedi also addressed the physical topology changes driving optics deeper into clusters. As GPU servers densify, they “shove out everything except compute,” and the topology shifts: traditional top-of-rack switching becomes less central, while optical reach extends from meters to 30–50 meters, pushing more optics into intra-row and row-scale fabrics. He noted the scale of optics consumption is changing so rapidly that he “doesn’t bother updating the numbers,” because they shift materially every few months—his shorthand for how quickly bandwidth density, lane counts, and fiber management complexity are compounding in real deployments.
He then walked through two Nvidia CPO switch implementations as examples of packaging tradeoffs among density, serviceability, and manufacturability. One design used a socketized electrical interface with permanently attached fiber, while the newer, higher-density design moved toward patchable fiber enabled by smaller pitch and more mature packaging/assembly methods. The through-line was densification without proportional growth in physical size—more lanes, more aggregate bandwidth, and better manufacturability in roughly the same footprint—by advancing packaging and optical integration together rather than treating them as separate subsystems.
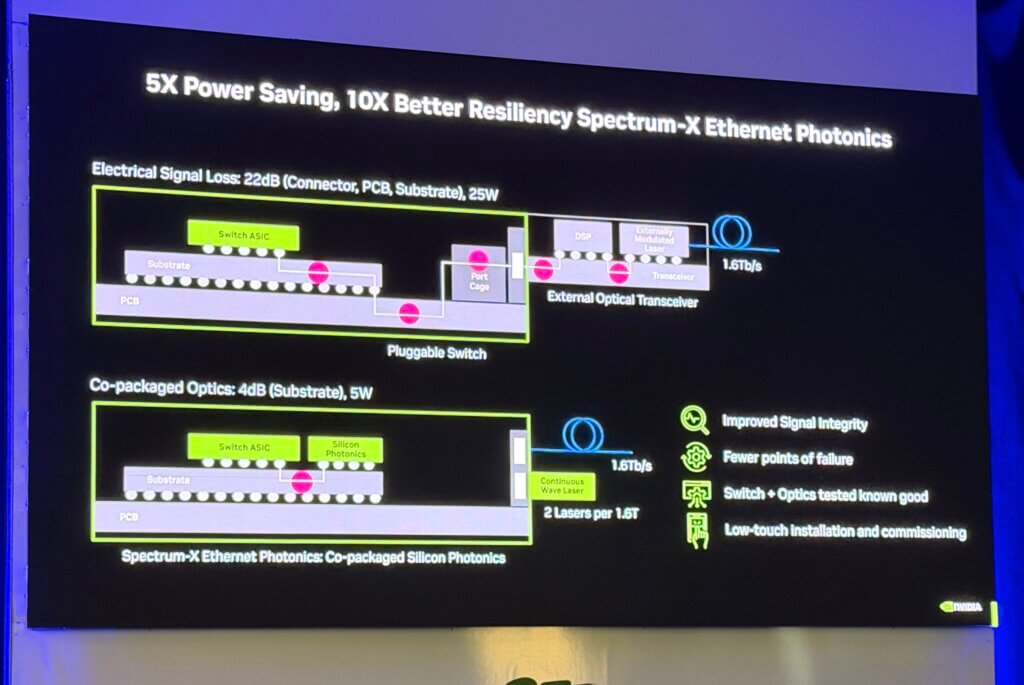
A technical—and economically pointed—section of the talk focused on energy per bit. Seyedi argued that every additional interface prior to going optical is effectively a “currency exchange” that adds overhead, and that pushing optics closer to the source—particularly through optics-in-the-box and co-packaged designs—reduces power per bit materially. He described a roughly fivefold swing in efficiency between less integrated and more integrated optical approaches, and tied that directly to AI economics: power spent moving bits is power not available for compute, and in power-constrained facilities that tradeoff maps to revenue capacity.
Seyedi also tackled a common reliability objection to CPO: concern that failures force replacement of an entire switch rather than a single pluggable module. He reframed that through fleet-scale failure-rate math, arguing that even a small annual failure rate for pluggables becomes operationally significant when multiplied across millions of optics, producing steady daily churn and associated GPU downtime. In contrast, he suggested that a CPO-style approach could reduce operational blast radius by shifting from frequent module-level interventions to rarer chassis-level events—assuming silicon photonics reliability behaves like mature silicon. He referenced public hyperscaler discussions (including Meta and Google) around failure rates and maintainability tradeoffs, and argued that silicon photonics can be qualified with methodologies analogous to advanced CMOS—his shorthand being “silicon is silicon” in terms of long-life expectations.
Finally, Seyedi emphasized serviceability details often lost in the headline debate. In his framing, an integrated, liquid-cooled laser module “in the box” can be replaced without the fiber-management overhead that makes pluggable swaps operationally awkward at scale—again reinforcing that manufacturability and operations are now first-class design constraints.
🌐 We’re tracking the rapid transition from pluggables to integrated optics—co-packaged optics, optics-in-the-box, and photonic fabrics—across AI-scale Ethernet and InfiniBand networks, including tail-latency engineering, manufacturability, and power-per-bit trends in next-generation AI factories. Follow our ongoing coverage at ConvergeDigest.com under AI Infrastructure, Optical, and Data Centers.