Google detailed a major expansion of its AI infrastructure stack with the introduction of eighth-generation Tensor Processing Units (TPUs) and a redesigned system architecture aimed at supporting planet-scale training and inference workloads, including clusters that can scale beyond one million accelerators.
The announcement, presented by Amin Vahdat, positions AI infrastructure as a tightly integrated system spanning silicon, networking, storage, and software orchestration. The company emphasized that emerging workloads—particularly Mixture-of-Experts (MoE) models, long-context reasoning systems, and agentic AI—require a fundamental redesign of compute infrastructure.
Google’s eighth-generation TPU family introduces two specialized systems—TPU 8t for large-scale training and TPU 8i for inference and reasoning—alongside upgrades to networking, storage, and system software under its broader AI Hypercomputer architecture.
Specialized TPU Architecture for Training and Inference
Google is explicitly separating infrastructure for different phases of the AI lifecycle:
- TPU 8t (training): optimized for large-scale pre-training and embedding-heavy workloads
- TPU 8i (inference): designed for post-training, real-time serving, and agentic reasoning
This reflects a shift away from unified accelerator designs toward workload-specific architectures, as training, fine-tuning, and inference increasingly diverge in their performance requirements.
Both systems integrate Arm-based Axion CPUs, which Google says eliminate host-side bottlenecks by accelerating data preprocessing and orchestration, ensuring that accelerators remain fully utilized.
TPU 8t: Optimized for Frontier Model Training
The TPU 8t platform targets large-scale model training, including LLMs and MoE architectures, with a focus on maximizing throughput and utilization across massive clusters.

Key architectural advancements include:
- SparseCore acceleration: a dedicated engine for embedding lookups and irregular memory access patterns, offloading operations that typically create bottlenecks in general-purpose accelerators
- Improved MXU/VPU balance: enabling better overlap of vector operations (e.g., softmax, layer normalization) with matrix computations to increase effective FLOPs utilization
- Native FP4 support: introducing 4-bit floating point precision to reduce memory bandwidth pressure and improve compute efficiency while maintaining model accuracy
At the system level, TPU 8t scales to 9,600 chips in a single superpod, using a 3D torus topology for intra-cluster communication.
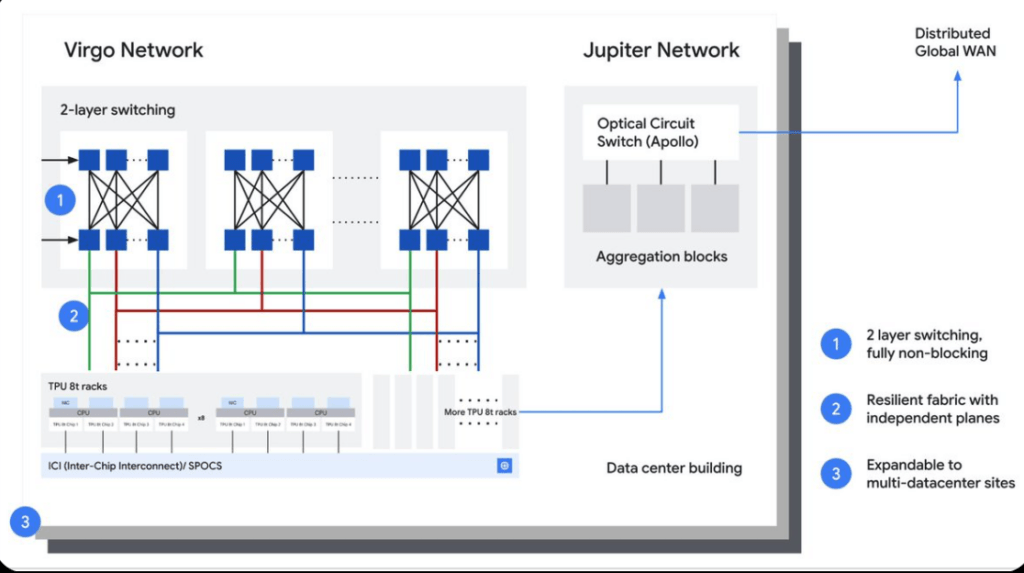
Virgo Network: Scaling AI Beyond the Data Center
To support these large-scale systems, Google introduced the Virgo Network, a new scale-out fabric designed for AI workloads.
Virgo features:
- Up to 4× increase in data center network bandwidth over the prior generation
- A flat, two-layer non-blocking topology built on high-radix switches
- Multi-planar design with independent control domains for improved reliability
- Up to 47 petabits/sec of non-blocking bisection bandwidth
The architecture reduces latency by minimizing network tiers and supports over 134,000 TPUs in a single fabric domain. Using orchestration frameworks such as JAX and Pathways, Google said it can scale training workloads across more than one million TPU chips, effectively creating a distributed supercomputer.
Eliminating Data Bottlenecks: TPUDirect and Storage Advances
Google is also addressing data movement bottlenecks, a key constraint in large-scale training:
- TPUDirect RDMA enables direct transfers between TPU memory and network interfaces, bypassing host CPUs
- TPUDirect Storage allows direct access to high-speed storage systems such as managed Lustre
Combined with 10 TB/sec-class storage systems, these technologies allow data to be streamed directly into TPU memory at line rate. Google said this results in up to 10× faster storage access compared to the prior-generation Ironwood TPUs, ensuring that compute units remain fully utilized even with large multimodal datasets.
TPU 8i: Built for Agentic AI and High-Concurrency Inference
The TPU 8i platform is optimized for inference, particularly workloads involving long-context reasoning and agent-based execution.
Key innovations include:
- 3× larger on-chip SRAM, enabling full key-value (KV) cache storage on-chip for faster long-context decoding
- Collectives Acceleration Engine (CAE), which reduces synchronization latency by up to 5×, accelerating operations required for autoregressive decoding and chain-of-thought reasoning
- Replacement of prior SparseCore units with CAE in inference configurations, reflecting different workload requirements
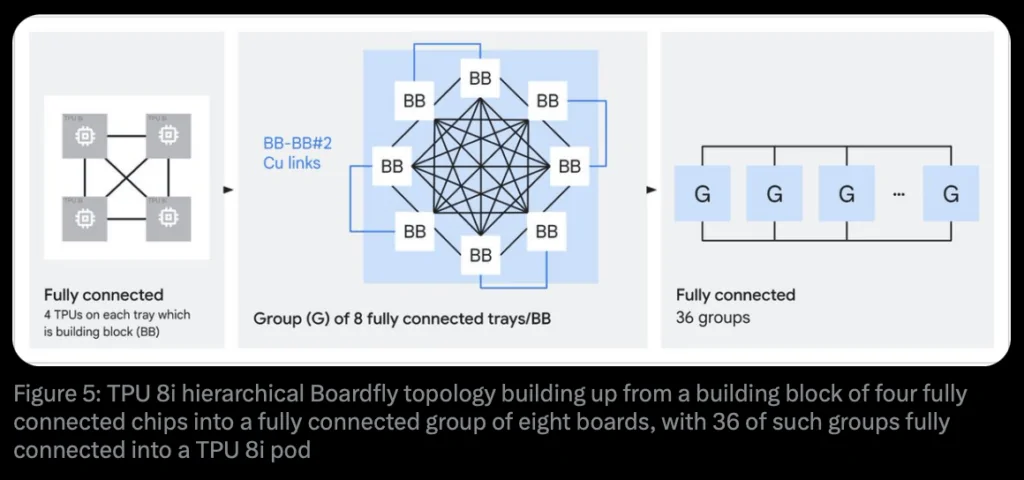
Boardfly Topology for Low-Latency Communication
TPU 8i introduces a new Boardfly interconnect topology, replacing the 3D torus used in training systems.
- Reduces network diameter from 16 hops (torus) to 7 hops in a 1,024-chip system
- Uses a high-radix, hierarchical design inspired by Dragonfly architectures
- Connects up to 1,152 chips per pod with optical circuit switching
This reduces communication latency by up to 50% for all-to-all workloads, which are common in MoE and reasoning models where tokens must be dynamically routed between chips.
Software Stack and Performance Gains
Google emphasized tight hardware-software co-design, with support across:
- JAX, PyTorch (native support in preview), and Keras
- XLA compiler for automatic optimization
- Pallas and Mosaic for custom kernel development
The company reported significant generation-over-generation improvements versus its prior Ironwood TPU platform:
- Up to 2.7× improvement in training price-performance (TPU 8t)
- Up to 80% improvement in inference price-performance (TPU 8i)
- Up to 2× improvement in performance-per-watt
Heterogeneous Infrastructure: TPUs and GPUs
In parallel, Google confirmed continued support for GPU-based workloads, including systems based on NVIDIAarchitectures such as Vera Rubin NVL72.
The company’s strategy is to support a heterogeneous compute environment, where TPUs, GPUs, and CPUs are orchestrated together under the AI Hypercomputer framework, allowing customers to select the optimal architecture for each workload.
Analysis: Infrastructure Redesign for the Agentic Era
Google’s eighth-generation TPU announcement reflects a broader shift in AI infrastructure design.
Key trends include:
- Workload specialization: Training and inference now require fundamentally different hardware architectures
- Network-first scaling: Interconnect design is becoming the primary determinant of system performance at scale
- Data movement optimization: Direct memory and storage access are critical to sustaining accelerator utilization
- Agentic workload demands: Reasoning systems and multi-agent environments introduce new latency and concurrency requirements
Google’s emphasis on world models and agentic AI suggests that future infrastructure must support continuous simulation, planning, and feedback loops—workloads that differ significantly from traditional batch training or transactional inference.
By combining specialized silicon, a high-performance network fabric, and deep software integration, Google is positioning its platform to support large-scale AI systems operating across distributed environments.
Customer Workloads Validate Infrastructure Strategy
Google pointed to a range of large-scale deployments to illustrate real-world usage:
- Axia Energia is using TPU clusters for advanced weather modeling to predict and mitigate power outages
- Woven by Toyota has achieved faster training for models predicting complex traffic scenarios
- The U.S. Department of Energy is deploying AI systems across its national labs to accelerate scientific discovery
- Boston Dynamics is training vision-language models for robotics applications
- In financial services, Citadel Securities is using TPU-based infrastructure to accelerate quantitative research, reducing workloads from days or weeks to hours or minutes while lowering costs.
Google Cloud as Preferred Nvidia Destination

Amin Vahdat also underscored Google Cloud’s continued alignment with NVIDIA, emphasizing that the platform is designed to support a heterogeneous compute model rather than a TPU-only strategy. He noted that Google Cloud remains a preferred destination for large-scale NVIDIA GPU deployments and announced that it will be among the first providers to offer the Vera Rubin NVL72 systems, targeting high-interactivity and long-context AI workloads. The message was pragmatic: while Google continues to advance its own TPU roadmap, it is equally investing in deep integration with NVIDIA’s latest architectures, allowing customers to choose the optimal mix of accelerators for training, inference, and specialized workloads. This reinforces Google’s broader positioning of the AI Hypercomputer as a flexible, multi-architecture platform, where TPUs, GPUs, and CPUs are orchestrated together to deliver performance at scale.
| Comparison: Google TPU 8th Generation vs. Ironwood | |||
| Category | TPU 8t (Training) | TPU 8i (Inference) | Ironwood (Prior Gen) |
|---|---|---|---|
| Primary Use Case | Frontier model training | Inference, agentic workloads, RL | General-purpose training & inference |
| Architecture Approach | Training-optimized, high throughput | Low-latency, high concurrency | Unified architecture |
| Max Pod Scale | ~9,600 TPUs | ~1,152 TPUs | 256 TPUs (typical pod) |
| Compute Performance | ~3× improvement vs prior gen | ~9–10× pod-level scaling improvement | Baseline for comparison |
| Memory (HBM) | Up to ~2 PB per superpod | Optimized for long-context inference | Significantly lower capacity |
| Interconnect / Topology | Enhanced 3D torus | New inference-optimized fabric | Earlier-gen interconnect |
| Cluster Scaling | Hundreds of thousands to 1M+ TPUs (via Virgo) | Millions of concurrent agents | Limited multi-pod scaling |
| Networking Fabric | Virgo (47 Pb/s, multi-DC scaling) | Virgo-enabled inference scaling | Pre-Virgo fabric |
| Target Workload Evolution | Frontier LLMs, large-scale training | Agentic AI, real-time systems | Earlier generation AI workloads |