Toronto-based Taalas has emerged from stealth with more than $200 million in funding and introduced its first product, a hard-wired implementation of Llama 3.1 8B running on custom silicon. In a blog post titled “The path to ubiquitous AI,” CEO Ljubisa Bajic outlined a plan to reduce inference latency and system cost by converting individual AI models directly into dedicated chips. The company reported the funding figure in dollars but did not specify whether it is USD or CAD.
Founded approximately 2.5 years ago, Taalas developed a platform that converts a previously unseen AI model into custom silicon in about two months. Its architecture centers on full model specialization, merging storage and compute on a single die at DRAM-level density, and eliminating reliance on high-bandwidth memory (HBM), advanced packaging, 3D stacking, liquid cooling, and high-speed I/O. By removing the traditional boundary between off-chip DRAM and on-chip compute, the company aims to reduce complexity, power consumption, and total system cost.
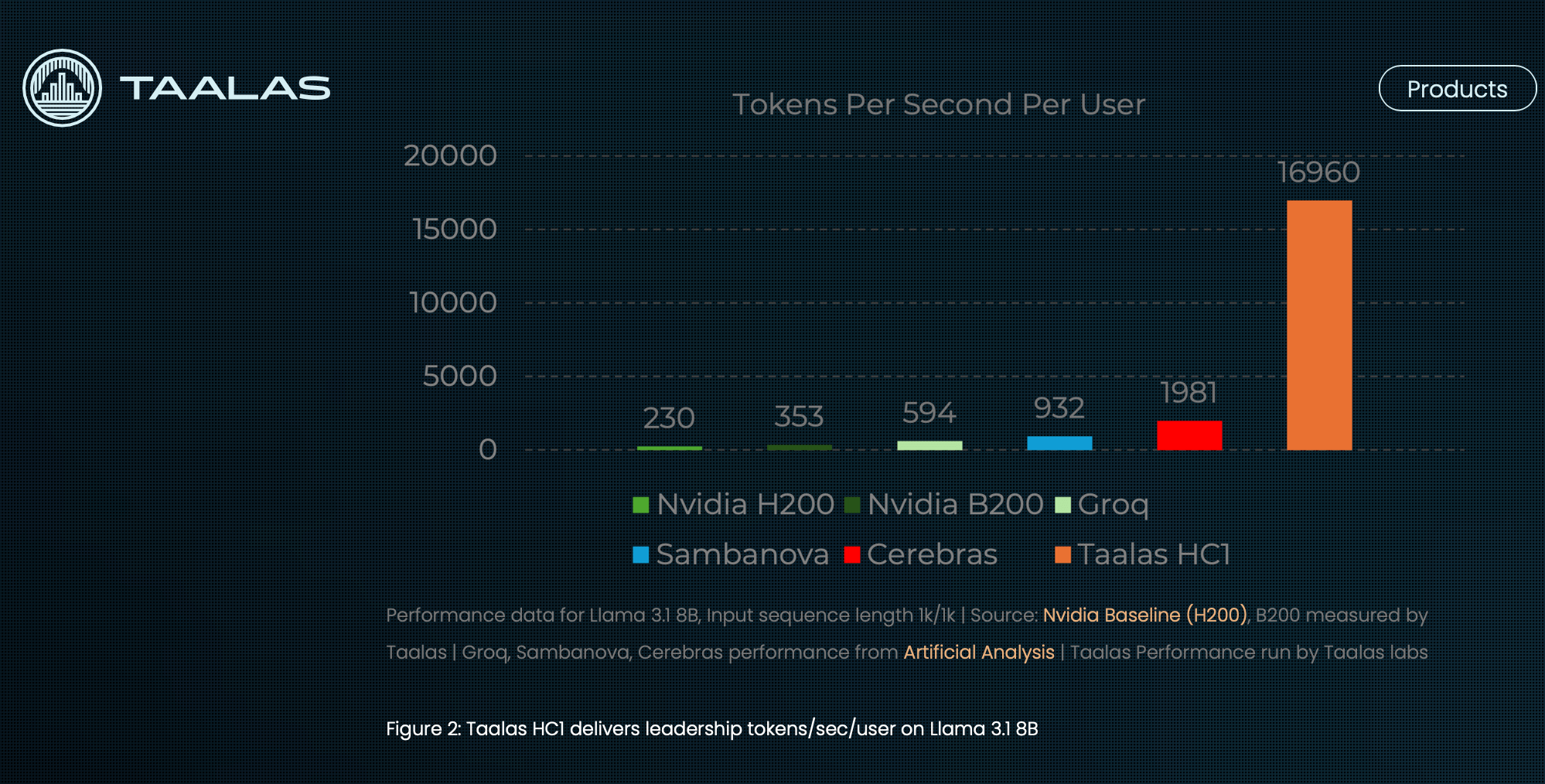
The first product, the HC1 board, runs a hardened version of Llama 3.1 8B as both a chatbot demo and an inference API service. Taalas reports 17,000 tokens per second per user, nearly 10x faster than GPU-based baselines, while consuming 10x less power and costing 20x less to build. The initial silicon uses a custom 3-bit base data type with a mix of 3-bit and 6-bit quantization, introducing some quality tradeoffs. A second-generation platform (HC2) will adopt standard 4-bit floating-point formats and target higher density and faster execution, with a frontier-scale LLM planned for winter deployment.
• More than $200 million raised; currency not specified
• Headquartered in Toronto; 24 employees listed on LinkedIn
• First product developed with ~$30 million of total capital raised
• Converts AI models to custom silicon in roughly two months
• HC1 hard-wired to Llama 3.1 8B; configurable context window and LoRA fine-tuning support
• Reports 17K tokens/sec per user; ~10x speed, 10x lower power, 20x lower build cost
• HC2 platform and frontier model planned for winter
“Our first product was brought to the world by a team of 24 team members, and a total of just $30M spent, of more than $200M raised. This achievement demonstrates that precisely defined goals and disciplined focus achieve what brute force cannot,” said Ljubisa Bajic, CEO of Taalas.
🌐 Analysis: Taalas describes itself as a lean, engineering-focused startup built by long-time collaborators, many of whom have worked together for more than 20 years. The company lists Toronto as its headquarters and 24 employees on LinkedIn, aligning with Bajic’s statement that the first product was delivered by a 24-person team. While Taalas has disclosed total capital raised, it has not publicly detailed its investor roster or ownership structure in its launch materials. The capital efficiency claim—shipping first silicon with roughly $30 million spent—stands out in an AI hardware sector where multi-hundred-million-dollar burn rates are common.
CEO Ljubisa Bajic previously worked at Tenstorrent, a Toronto-based AI processor startup known for its RISC-V–based architectures and backing from high-profile semiconductor investors. Tenstorrent has pursued programmable AI accelerators targeting both training and inference. In contrast, Taalas advocates fixed-function, per-model silicon optimized for inference only. The shift from programmable accelerators to fully specialized “hardcore models” reflects a different architectural thesis: that extreme efficiency gains require abandoning general-purpose flexibility in favor of model-specific hardware.
Taalas enters a competitive inference silicon landscape that includes GPU incumbents and specialized accelerators from NVIDIA, Groq, Cerebras, and SambaNova Systems. While mainstream roadmaps emphasize scale-out clusters, HBM bandwidth, and software programmability, Taalas positions total specialization and unified storage/compute as a way to compress latency and shrink system footprints. Market adoption will depend on how rapidly the company can retarget silicon to evolving model architectures while preserving its reported gains in performance-per-watt and cost.
In December 2025, NVIDIA struck an agreement with Groq valued at about US $20 billion to license Groq’s inference technology and bring over key personnel, including Groq’s founder and senior team, into NVIDIA.



