The CXL Consortium released the Compute Express Link 4.0 specification, doubling interconnect bandwidth from 64GT/s to 128GT/s as data centers confront heavier AI, HPC, and memory-intensive workloads. The update builds on PCIe 7.0 signaling and preserves the 256-byte Flit structure introduced in CXL 3.x, enabling vendors to scale performance without re-architecting device software models.
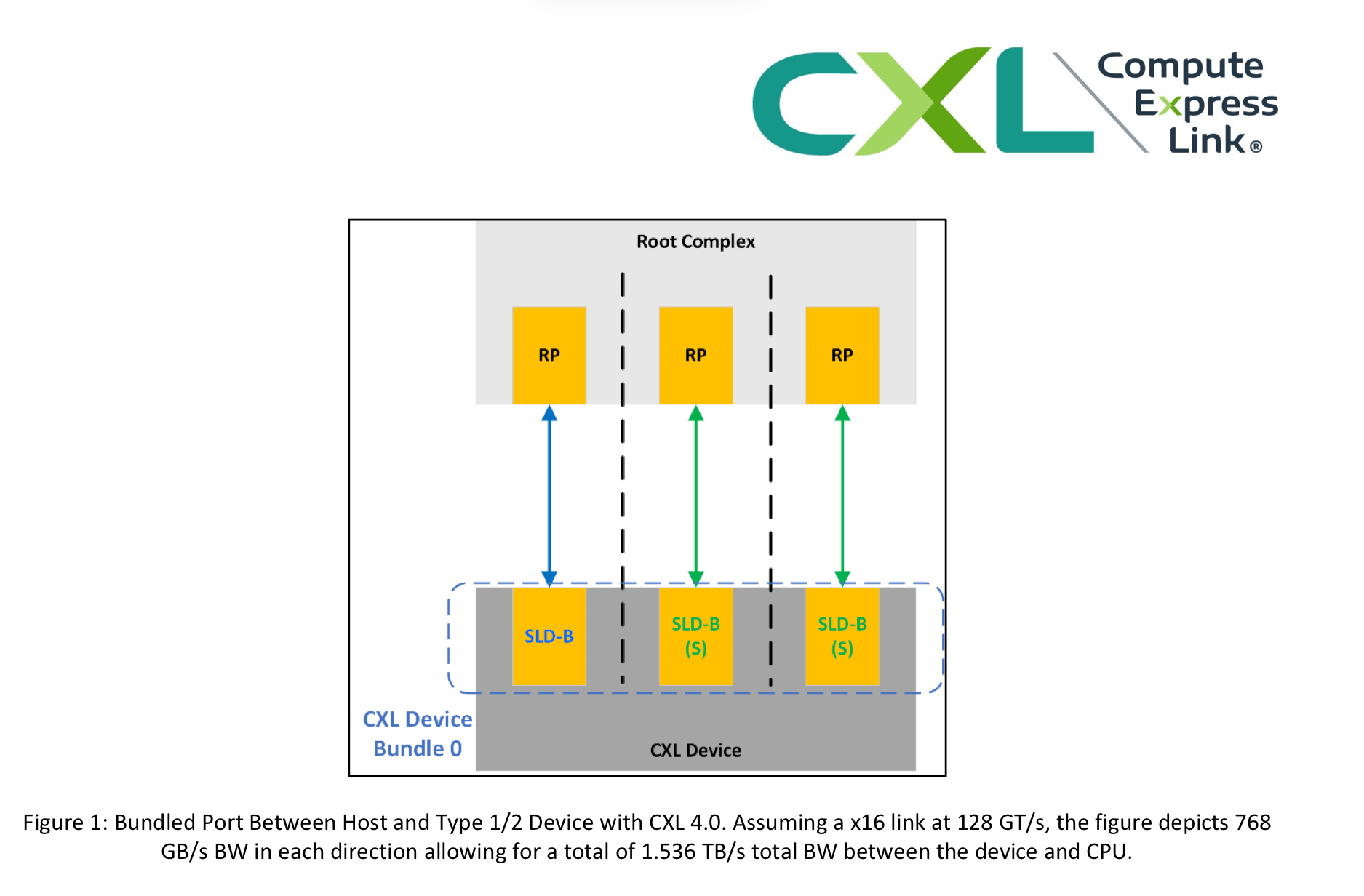
CXL 4.0 introduces Bundled Port capabilities that allow multiple physical ports to operate as a single logical entity, giving hosts and accelerators higher aggregate throughput without added latency. The specification also adds support for native x2 link width to increase fan-out, plus up to four retimers to extend channel reach for complex topologies such as large accelerators, multi-host fabrics, and memory pooling systems.
The new specification also strengthens memory RAS. Enhancements include finer-grained corrected error reporting during patrol scrubs, host-initiated Post Package Repair flows at boot, and flexible memory sparing operations that can be triggered immediately or deferred. CXL maintains full backward compatibility with all previous versions.
Consortium members are demonstrating CXL 4.0 silicon and platform concepts at SC25 in St. Louis. A Birds of a Feather session on November 18 will explore how CXL memory pooling and sharing can accelerate AI and HPC workloads. A deep-dive webinar on December 4 will cover the new features in detail.
• Bandwidth doubles to 128GT/s with zero added latency
• Introduces Bundled Ports for logical aggregation of multiple device links
• Supports native x2 link width and up to four retimers to extend reach
• Enhances memory RAS with improved error reporting and maintenance workflows
• Backward compatible with CXL 3.x, 2.0, 1.1, and 1.0
• CXL Pavilion (Booth #817) hosting live demos at SC25
“The release of the CXL 4.0 specification sets a new milestone for advancing coherent memory connectivity, doubling the bandwidth over the previous generation with powerful new features,” said Derek Rohde, CXL Consortium President and Treasurer, and Principal Engineer at NVIDIA.
🌐 Analysis: CXL 4.0 arrives at a time when AI supercomputers, GPU memory fabrics, and disaggregated architectures demand far higher bandwidth-per-device. The introduction of Bundled Ports and expanded reach aligns with the direction hyperscalers and accelerator vendors are taking as they design next-generation memory pooling and shared GPU-memory spaces. Demonstrations at SC25 reinforce CXL’s push to remain central in heterogeneous AI systems as vendors compare CXL’s roadmap with alternatives such as NVLink, Infinity Fabric, and proprietary memory fabrics.
Explainer: What CXL Is and Why It Matters
Compute Express Link (CXL) is an open, high-speed interconnect designed to link CPUs, GPUs, accelerators, and memory devices using a coherent, low-latency interface. Built on top of PCIe electricals, CXL enables shared memory semantics and efficient data movement between heterogeneous compute elements—critical for AI training engines, inference clusters, memory expanders, and composable infrastructure. Modern AI and HPC workloads rely on massive memory footprints and fast exchange of model parameters, placing pressure on traditional memory channels. CXL addresses this by allowing pooled, tiered, or disaggregated memory resources to operate with coherence, reducing the need for overprovisioned DRAM and improving system utilization.
The technology also supports dynamic system architectures, including memory pooling for large language model training, GPU/accelerator sharing, multi-host fabrics, and rack-scale composition of resources. With the latest 4.0 release, CXL pushes performance to 128GT/s while adding architectural tools like Bundled Ports, longer reach, and more robust memory maintenance. As hyperscalers evaluate how to balance proprietary fabrics (NVLink, Infinity Fabric) with open standards, CXL continues to gain traction as the neutral, industry-wide path for scalable memory and accelerator connectivity.
CXL Consortium Overview and Key Members
The CXL Consortium formed in 2019 to develop an open standard for coherent interconnects and promote interoperability across the data center ecosystem. Founding members included Alibaba, Cisco, Dell Technologies, Facebook (now Meta), Google, Hewlett Packard Enterprise, Huawei, Intel, and Microsoft. The Consortium has since expanded to hundreds of companies spanning silicon vendors, system OEMs, hyperscalers, cloud providers, and memory manufacturers. Major contributing members today include AMD, NVIDIA, Arm, Samsung, SK hynix, Micron, Broadcom, Marvell, Lenovo, IBM, Kioxia, and Qualcomm—reflecting broad industry alignment behind the CXL roadmap and its role in next-generation AI and HPC architectures.
🌐 We’re tracking the latest developments in semiconductors. Follow our ongoing coverage at: https://convergedigest.com/category/semiconductors/
🌐 We’re launching the “Data Center Networking for AI” series on NextGenInfra.io and inviting companies building real solutions—silicon, optics, fabrics, switches, software, orchestration—to share their views on video and in our expert report. To get involved, send a note to [email protected] or [email protected].





