Broadcom Outlines Optical Scale-Up Strategy for AI Fabrics, Backs New OCI MSA
At the Optica Executive Forum in Los Angeles on Monday, Broadcom’s Near Margalit argued that the next phase of AI infrastructure design will depend on treating scale-up and scale-out more as a continuum rather than as isolated network domains. His central point was that conventional Clos-based scale-out architectures become increasingly inefficient as XPU cluster sizes rise, requiring multiple switching layers, large numbers of optical transceivers, extensive connectivity, and significant power just to move data across the fabric.
Margalit said one way to reduce that complexity is to expand the scale-up domain itself and use Ethernet-based technology to make it part of the larger system fabric. Instead of treating every GPU or accelerator as an independent endpoint in the scale-out network, he suggested operators can think in terms of pods. In his example, if a pod contains roughly 1,000 XPUs, then a million-XPU system could be built from 1,000 such pods, with the broader network designed around pod-level interconnection rather than direct node-by-node scaling. The goal is to reduce the number of layers needed in the scale-out fabric while preserving the high-bandwidth, low-latency characteristics required inside the scale-up domain.
A major part of his presentation focused on the optical interconnect choices needed to make that possible. He said copper alone will struggle to extend to 1,000-node or larger scale-up networks, pushing the industry toward optics. But he also argued that not every optical path is practical. Traditional DR-style optics, moving from 100G to 200G and now 400G per fiber, are following the IEEE roadmap but may be difficult to extend much further efficiently. Margalit said scale-up networks are especially sensitive because their bandwidth demands are roughly an order of magnitude greater than scale-out networks, making every picojoule per bit matter. He estimated that even with low-power optics, total I/O energy can approach 10 pJ/bit once both the optics and the copper SerDes reach are included.
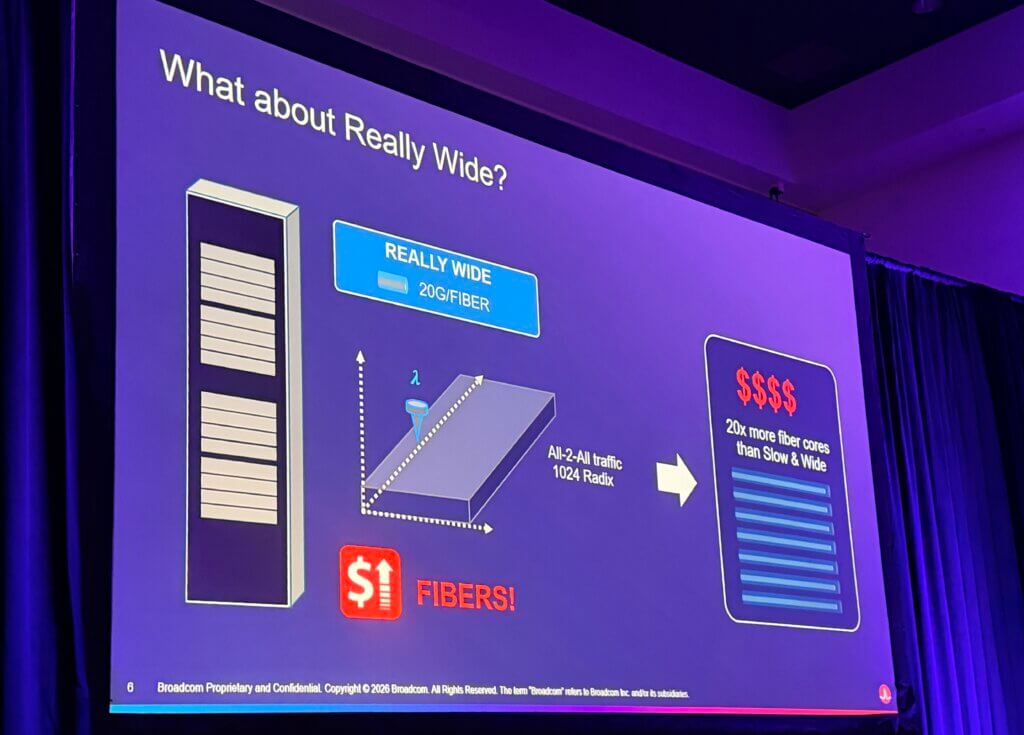
He also walked through the tradeoffs between “slow and wide,” “fast and wide,” and very wide optical approaches. Wide wavelength-comb architectures can lower power, he said, but they introduce complexity in laser sources and control structures. By contrast, a “fast and wide” approach—such as 16 wavelengths at 400G—would imply 6.4 Tbps per port and would require a 6.6 Pb/s switch for a 1024-radix design, far beyond today’s commercially available silicon. On another extreme, very low-speed, very wide optical schemes may reduce energy, but they create a fiber-management problem because true scale-up networks require large-scale shuffling and connectorization, not simple point-to-point links. In that case, fiber count becomes the limiting factor.
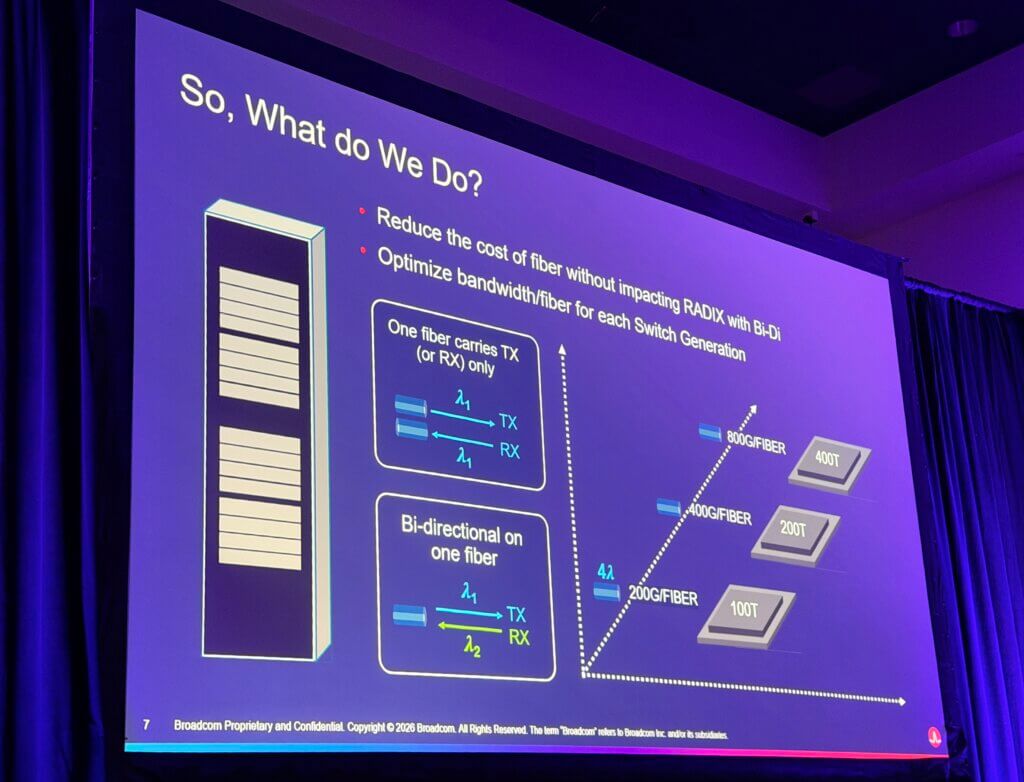
Broadcom’s proposed middle path is to reduce fiber cost without sacrificing radix by using bidirectional transmission on a single fiber and by matching bandwidth-per-fiber to practical switch sizes. Margalit described this as an “easy win,” noting that BiDi is already well understood in other markets. His rule of thumb was that 100 Tb/s-class switches align more naturally with roughly 200G per fiber, while 200 Tb/s switches align with roughly 400G per fiber. That framing underpins the newly announced Optical Compute Interconnect MSA, or OCI MSA, which Broadcom launched with a group of high-profile partners to define an optical scale-up architecture built around open standards, low-speed NRZ signaling, conventional DFB lasers, and Ethernet-based operation across larger AI domains.
Key points
- Broadcom argued that conventional “fast and narrow” optical scale-up at 400G per fiber runs into practical scaling limits beyond 400G.
- A “fast and wide” model at 6.4 Tb/s per fiber would imply a 6.6 Pb/s switch for 1024-radix connectivity, which the company characterized as 64x larger than any commercially available switch.
- A “really wide” approach at 20G per fiber could sharply increase fiber count, with one slide warning of roughly 20x more fiber cores than a more balanced alternative.
- Broadcom proposed BiDi as a way to reduce fiber cost while preserving radix, allowing one fiber to carry traffic in both directions.
- The company’s bandwidth-per-fiber roadmap slide mapped about 200G/fiber to 100T-class switching, 400G/fiber to 200T, and 800G/fiber to 400T.
- A final slide highlighted the formation of the OCI-MSA on March 12, 2026, with founding members shown as Meta, Microsoft, OpenAI, AMD, Broadcom, and NVIDIA.
- Broadcom positioned OCI-MSA as a framework to move optical scale-up from in-rack deployments to multi-rack and multi-row AI systems.
“The switch and the optics have to be married together, and they have to match. You can’t get one ahead of the other one if you want to maintain radix and bandwidth.”