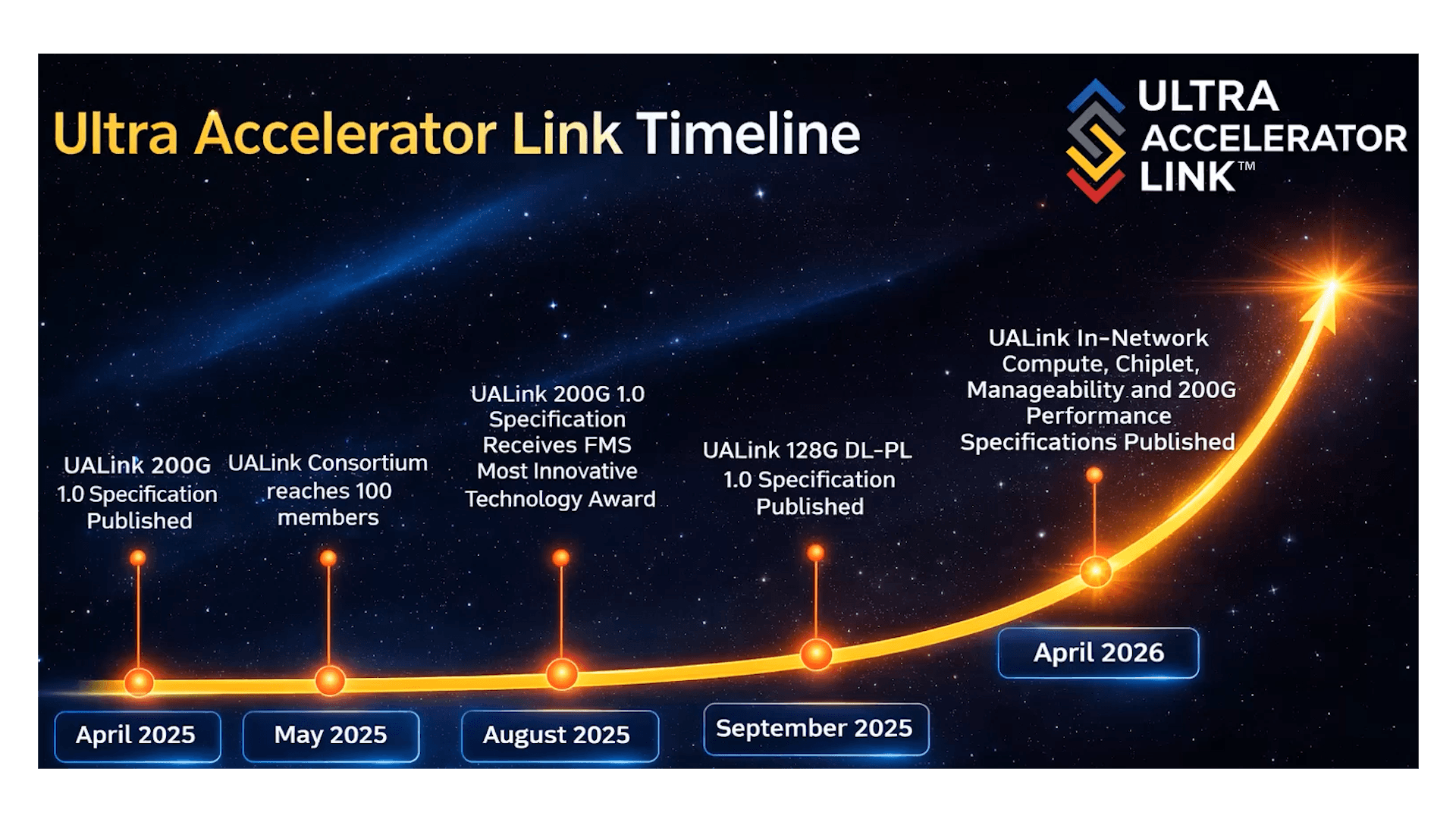
The UALink Consortium released a new set of specifications that expand its open scale-up interconnect framework for AI infrastructure, adding support for in-network compute, chiplet integration, and centralized manageability. The update reflects ongoing industry efforts to standardize high-performance accelerator interconnects as AI workloads scale across increasingly complex, multi-node systems.
The latest release introduces UALink Common Specification 2.0, which adds in-network compute capabilities designed to enable computation directly within the interconnect fabric. This approach targets reduced latency and improved bandwidth efficiency for distributed AI training and inference. In parallel, the consortium separated the Data Link and Physical Layer (DL/PL) Specification 2.0, enabling faster iteration on physical layer advancements, including 200G signaling, without requiring changes to higher-level protocol layers.
Additional specifications address system-level integration and operational control. The Manageability Specification 1.0 defines centralized control and telemetry using standard interfaces such as gNMI, YANG, SAI, and Redfish. Meanwhile, the Chiplet Specification 1.0 aligns UALink with emerging chiplet-based architectures, including compatibility with the UCIe Consortium 3.0 specification, providing standardized interfaces and management for integrating UALink into modular SoCs.
- UALink Common Specification 2.0 introduces in-network compute to reduce latency and improve scaling efficiency for AI workloads
- UALink DL/PL Specification 2.0 enables independent evolution of physical layers, including 200G performance
- Manageability Specification 1.0 defines centralized control using gNMI, YANG, SAI, and Redfish APIs
- Chiplet Specification 1.0 enables integration into chiplet-based SoCs with compliance to UCIe 3.0
- Specifications are designed to support multi-vendor interoperability and open ecosystem development
“As AI workloads continue to outpace traditional interconnect timelines, we are pleased to deliver an essential update to the UALink Specifications,” said Kurtis Bowman, Board Chair of the UALink Consortium. “The advancements to UALink technology introduced in this release will enable the industry to quickly and efficiently integrate UALink solutions into their architectures.”
🌐 Analysis: The UALink roadmap continues to position itself as an open alternative to proprietary scale-up interconnects such as NVIDIA’s NVLink, with increasing emphasis on system-level capabilities like in-network compute and standardized manageability. The addition of chiplet alignment and 200G-ready physical layers reflects broader industry shifts toward disaggregated silicon and higher radix, lower-latency fabrics for AI clusters, aligning with parallel efforts across UCIe, Ethernet-based AI fabrics, and emerging optical interconnect strategies.
Video: UALink 2.0: Open GPU Interconnect for AI Clusters

Kurtis Bowman, Chairman of the UALink Consortium, discusses how the organization addresses critical memory bandwidth challenges in rapidly expanding AI infrastructure. As AI clusters scale from individual servers to entire data centers, the need for efficient GPU interconnection becomes paramount. Bowman explains how UALink’s open architecture provides a competitive alternative for AI scale-up environments, offering the performance characteristics necessary for both training and inference workloads. In this session, Bowman reveals the UALink Consortium’s newly released Specification 2.0, which introduces significant architectural improvements including in-network compute capabilities and a modular design that separates protocol layers from physical interfaces. He outlines how this separation enables future speed scalability without requiring software changes, and discusses the consortium’s approach to industry-standard management tools and chiplet integration. With over 115 member companies and products expected in 2027, Bowman positions UALink as a key enabler for next-generation AI infrastructure.
**What You Will Learn:** –
– How memory bandwidth limitations impact AI cluster performance and why traditional CPU solutions don’t apply to GPU environments
– The competitive advantages of UALink’s open architecture compared to proprietary interconnect solutions
– Key features in Specification 2.0, including in-network compute and protocol layer separation
– How UALink integrates with industry-standard management tools and UCIE chiplet specifications
– The consortium’s product roadmap and timeline for commercial availability
📚 CHAPTERS: 0:00:00 – Introduction: AI Clusters and the Memory Bandwidth Challenge
0:01:15 – UALink’s Open Architecture and Competitive Advantages
0:02:56 – Consortium Growth and Industry Adoption
0:04:10 – Specification 2.0: Modular Design and In-Network Compute
0:06:00 – Protocol Layer Separation for Future Speed Scalability
0:07:20 – Management Standards and Industry Tool Integration
0:08:46 – Chiplet Specification and UCIE Integration
0:09:56 – Product Roadmap and Future Development Timeline
0:10:42 – Summary: UALink’s Role in AI Infrastructure Evolution
🌐 We’re tracking the latest developments in AI infrastructure and data center networking. Follow our ongoing coverage at: https://convergedigest.com/category/data-center/