Following Friday’s sudden mandated withdrawal of Fable and Mythos, and in between FIFA World Cup matches, this weekend seemed like a good opportunity to revisit one of the most important infrastructure stories in AI. Over the past year, Anthropic and its ecosystem of partners have announced an extraordinary series of investments spanning custom silicon, hyperscale cloud infrastructure, merchant GPUs, optical networking, private-credit financing, and purpose-built AI data centers. What makes Anthropic particularly interesting is not simply the scale of these commitments, but the diversity of its technology stack. Unlike many of its peers, Anthropic is simultaneously leveraging AWS Trainium, Google TPUs, NVIDIA GPUs, neocloud providers, dedicated AI factories, and emerging financing structures to secure future compute capacity. The result is one of the most complex and diversified AI infrastructure strategies yet assembled. Here is our updated look at the major projects, partnerships, and architectural decisions announced to date—and what they reveal about where AI infrastructure is heading next
Anthropic now anchors one of the most heavily capitalized and diversified compute portfolios in frontier AI. The company’s strategy points to a deliberate multi-provider architecture rather than dependence on a single hyperscaler, accelerator vendor, or data center operator. By spreading capacity across custom cloud silicon (AWS Trainium, Google TPUs), merchant GPUs (NVIDIA), independent neoclouds, leased competitor capacity, and direct custom builds, Anthropic has decoupled frontier model development from any single supply-chain or interconnect bottleneck.
The sheer scale of these physical commitments is dictated by historic commercial velocity. Following its $65 billion Series H funding round in May 2026—which valued the company at approximately $965 billion post-money—Anthropic’s annualized run-rate revenue reportedly crossed $47 billion, up from roughly $9 billion at the end of 2025. The company has also reportedly submitted a confidential draft S-1 registration statement to the U.S. Securities and Exchange Commission, positioning itself for a potential public offering. This capital influx is designed to relieve the capacity constraints that periodically affected Claude availability during periods of peak demand.
Three Infrastructure Models Supporting Anthropic
Anthropic’s expansion now spans three distinct infrastructure models:
• Hyperscaler-owned AI infrastructure (AWS, Google Cloud, Azure)
• Independent AI factories and neoclouds (Fluidstack, CoreWeave, SpaceXAI)
• Private-credit financed AI infrastructure (Broadcom, Apollo, Blackstone AI XPV)
Together, these models represent one of the most ambitious AI infrastructure strategies announced to date.
Anthropic’s computing architecture has evolved well beyond conventional cloud rental agreements into a network of long-term infrastructure partnerships backed by hyperscale providers, AI-specialized cloud operators, semiconductor suppliers, and institutional capital.
Anthropic’s Multi-Provider Compute Infrastructure Matrix
An architecture engineered to balance custom cloud silicon, high-throughput fabrics, merchant GPUs, and private-credit asset backing across decoupled deployment pipelines.
| Partner / Ecosystem | Contractual Footprint & Scale | Architectural Intent & Interconnect Focus |
|---|---|---|
| Amazon Web Services Primary Training Cloud Project Rainier Anchor | Up to 5 GW contractual envelope supported by a multi-year >$100B AWS technology expenditure book. Near-term execution targets nearly 1 GW of combined Trainium2 and Trainium3 hardware deployed by the end of 2026. Trainium2 / Trn2 Trainium3 Trainium4 Graviton CPU Cores | Establishes an absolute custom silicon fallback while scaling localized topologies. Scale-up workloads leverage 12.8 Tbps NeuronLink fabrics inside 64-chip UltraServers, presenting a unified 6 TB memory pool. Scale-out utilizes petabit-capacity EFAv3 fabrics across a dedicated Indiana campus. |
| Google Cloud TPU Scaling Vector MEMS Switching Fabric | Active deployment targets >1 GW of localized capacity in 2026, granting structural access to up to 1 million TPUs. A separate April 2026 contract maps out an additional ~3.5 GW of next-generation custom TPU capacity coming online in 2027. Ironwood TPU (v7) 3D-Torus ICI Palomar/Apollo OCS | Maintains deep workload heterogeneity for commercial inference pipelines and multi-modal pre-training sequences. Tightly couples 64-chip custom cubes over copper ICI, scaling seamlessly into massive 9,216-chip pods using automated, software-driven Optical Circuit Switch (OCS) networking. |
| Broadcom / Apollo / Blackstone AI XPV Platform Securitized Debt SPV | Initial asset tranche of $35B directly underwrites an expansion of more than 1 GW of customized Anthropic hardware footprint. Long-range institutional vehicle targets >20 GW of multi-tenant compute infrastructure through 2028. Custom Broadcom XPUs Scale-Up Ethernet (SUE) Tomahawk 6 (102.4T) Jericho 4 Fabric | Decouples compute capital expenditure from Anthropic’s balance sheet by treating physical silicon assets like leasable, securitized corporate debt. Deploys an end-to-end, Ethernet-native merchant fabric architecture covering low-latency scale-up, high-density scale-out, and multi-site scale-across topologies. |
| Fluidstack Independent Colocation Custom AI Factories | A direct $50B multi-site domestic data center buildout, breaking ground on heavy industrial campuses throughout 2026. Backed by a $1.4B direct lease backstop execution tied directly to Cipher Mining infrastructure. Texas Campus New York Campus High-Density Liquid Cooling | Insulates Anthropic against traditional cloud provider multi-tenant capacity bottlenecks. Purpose-built, ring-fenced infrastructure campuses engineered exclusively around the extreme thermal density and scale-across latency parameters of Claude frontier runs. |
| Microsoft Azure / NVIDIA Hyperscale Merchant GPU Joint Optimizations | Contractual access mapping up to 1 GW of sovereign computing capacity tied directly to an established $30B Azure environment agreement. Underwritten by up to $15B in collective equity-to-compute partnership provisions. Grace Blackwell (GB200) Vera Rubin Platforms NVIDIA CUDA Ecosystem | Provides maximum merchant software flexibility to handle sudden pre-training burst spikes and low-latency enterprise client application demands. Enables native software-level hardware optimizations directly linking Claude’s attention mechanisms to NVIDIA’s next-generation tensor core architectures. |
| SpaceXAI (xAI) Colossus 1 Leaseback Stranded Asset Capture | Secures 100% exclusive control of the Memphis supercluster, delivering more than 300 MW of active power across over 220,000 GPUs within a 30-day window. Valued at approximately $1.25B/month through a defined May 2029 commitment envelope. NVIDIA H100 / H200 NVLink Scale-Up Spectrum-X Ethernet | Provides immediate capacity to relieve commercial system strain across Claude Pro and Claude Max tiers. Capitalizes on an active 11% utilization stall caused by multi-site scale-across latency flaws in xAI’s legacy networking layout, converting an asset into immediate liquidity. |
| CoreWeave Neocloud Allocation On-Demand Capacity | Multi-year, production-scale agreement designed to supply merchant accelerator nodes, phasing directly into active inference rotations through the latter half of 2026. Financial value remains undisclosed under mutual confidentiality terms. NVIDIA HGX Clusters InfiniBand Scale-Out On-Demand Claude Pipelines | Acts as an agile, hyperscaler-independent buffer to absorb distributed enterprise request traffic. Supplements foundational training facilities with specialized cloud nodes optimized specifically to isolate short-horizon fine-tuning pipelines. |
1. The AWS Anchor and Project Rainier
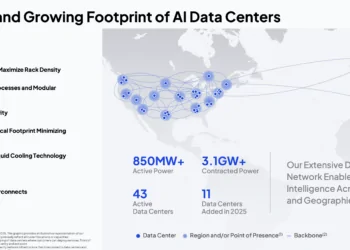
The structural foundation of Anthropic’s infrastructure portfolio remains its relationship with Amazon Web Services. Anthropic has committed to spending more than $100 billion over ten years on AWS technologies, securing a 5 GW capacity envelope. This represents a long-term deployment ceiling rather than immediate installed power and spans Trainium2 through Trainium4 silicon alongside tens of millions of Graviton CPU cores.
Near-term execution targets nearly 1 GW of combined Trainium2 and Trainium3 capacity fully operational by the end of 2026. Amazon has supported this expansion through a $5 billion equity investment, with additional investments tied to future milestones.
The physical centerpiece of the relationship is Project Rainier, AWS’s dedicated Anthropic supercluster anchored by an $11 billion campus in New Carlisle, Indiana. At activation, the facility contained nearly 500,000 Trainium2 chips and is expected to scale beyond one million accelerators supporting both training and inference workloads.

The networking architecture employs a two-tier design:
• Scale-Up: Trn2 UltraServers connect 64 Trainium2 processors through NeuronLink, AWS’s proprietary scale-up interconnect, exposing a unified memory pool of approximately 6 TB.
• Scale-Out: Third-generation Elastic Fabric Adapter (EFAv3) networking provides petabit-scale connectivity across UltraServers and between buildings.
This architecture allows many inference workloads to remain localized within a single UltraServer while enabling frontier-scale training across an entire campus.
2. Google Cloud and the TPU Optical Fabric
Google Cloud serves as another major training and inference platform for Anthropic. Under agreements announced in 2025 and 2026, Anthropic has access to up to one million TPUs and more than a gigawatt of active TPU capacity. A separate Google-Broadcom initiative is expected to add approximately 3.5 GW of next-generation TPU infrastructure beginning in 2027.
For networking professionals, Google’s interconnect architecture remains a key differentiator.
The Ironwood (v7) TPU connects 64 processors into a tightly integrated cube using a copper-based 3D torus Interconnect (ICI). These cubes are then connected into larger pods and superpods through a reconfigurable Optical Circuit Switch (OCS) fabric derived from Google’s MEMS-based switching technology.

A typical TPU superpod can deploy tens of thousands of optical interfaces across dozens of OCS systems. The optical fabric dynamically reconfigures network topology to optimize workload placement and route around failures, effectively functioning as a programmable optical backplane at hyperscale.
This architecture continues to drive demand for 800G and higher-speed optical interconnects throughout the AI infrastructure ecosystem.
3. Broadcom, Apollo, Blackstone: Financing as an Asset Class
One of the most significant developments in Anthropic’s infrastructure strategy occurred in June 2026 when Broadcom, Apollo, and Blackstone launched the AI XPV Platform.
The initiative is designed to support more than 20 GW of AI infrastructure through 2028 using Broadcom’s XPUs and networking technologies. The platform debuted with a $35 billion financing tranche led by Apollo and supported by Blackstone’s credit and insurance businesses. The initial deployment includes more than 1 GW of Anthropic-related infrastructure.
The significance extends beyond the hardware itself.
The AI XPV structure effectively transforms AI infrastructure into a financeable asset class. Through a private-credit SPV model, institutional capital finances the acquisition of compute infrastructure, which is then leased to AI operators such as Anthropic.
Importantly, the AI XPV infrastructure remains separate from Google’s TPU deployments. Broadcom therefore occupies two distinct roles within Anthropic’s ecosystem: supplier of XPUs and Ethernet networking through XPV deployments, and silicon design partner supporting Google’s next-generation TPU roadmap.
4. Direct Infrastructure via Fluidstack
Anthropic’s partnership with UK-based neocloud provider Fluidstack provides another layer of diversification.
The companies are collaborating on a $50 billion U.S. data center buildout spanning Texas and New York. These facilities are designed specifically around Anthropic’s compute, networking, cooling, and power requirements rather than traditional multi-tenant cloud deployments.
The project is expected to generate approximately 800 permanent jobs and 2,400 construction jobs. Anthropic has further supported the effort through lease guarantees tied to infrastructure projects involving Cipher Mining and through a strategic equity investment.
The Broadcom AI XPV platform is expected to provide a substantial portion of the hardware deployed within these campuses.
5. The SpaceXAI Colossus 1 Lease
One of the most surprising developments of 2026 involved SpaceXAI’s decision to lease the full compute capacity of its Memphis-based Colossus 1 supercomputer to Anthropic.
The agreement gives Anthropic immediate access to more than 300 MW of infrastructure spanning over 220,000 NVIDIA H100, H200, and GB200 GPUs. The capacity is expected to become available within roughly 30 days and provides an immediate mechanism for expanding Claude availability and enterprise inference capacity.
The broader significance may be what the deal reveals about AI infrastructure utilization.
Reports from The Information indicated that Colossus 1 struggled to achieve expected utilization levels, with Model FLOPs Utilization (MFU) reportedly hovering near 11%. Additional reporting suggested the deployment encountered significant latency challenges connecting the primary Memphis facility with auxiliary infrastructure sites located more than ten miles away.
xAI subsequently shifted portions of its frontier training activity toward newer Blackwell-based infrastructure. The Anthropic lease allows SpaceXAI to monetize a substantial installed asset while providing Anthropic with immediate access to large-scale GPU capacity.
6. CoreWeave
Anthropic also signed a multi-year infrastructure agreement with CoreWeave in April 2026.
Although financial details remain undisclosed, CoreWeave provides another source of merchant GPU capacity that can support both training and inference workloads. Capacity deployments are expected to ramp through the remainder of 2026 with options for future expansion.
The Workload-Match Strategy
Anthropic’s infrastructure approach is notable for its ability to dynamically map workloads across multiple hardware architectures.
• AWS Trainium: Used for large-scale baseline model training where custom silicon economics provide cost advantages.
• Google TPUs: Utilized for high-throughput inference and mixed training workloads that benefit from Google’s optical fabric architecture.
• NVIDIA GPUs (Azure, CoreWeave, SpaceXAI): Deployed for burst capacity, enterprise inference, and workloads requiring the flexibility of the NVIDIA software ecosystem.
Rather than optimizing Claude exclusively for a single hardware platform, Anthropic increasingly appears to be treating compute resources as a heterogeneous pool spanning multiple silicon architectures.
“Claude’s latest advancements have driven large-scale adoption among the world’s most demanding organizations,” said Krishna Rao, CFO of Anthropic. “This funding will help us serve the historic demand we are experiencing, stay at the research frontier, and bring Claude to more of the places where work happens.”
🌐 Analysis: Scaling Across the Final Frontier
Anthropic’s infrastructure strategy highlights two structural shifts reshaping the AI industry.
First, AI infrastructure has evolved into a financeable asset class. Through private-credit structures, independent AI factories, and direct data center ownership, Anthropic has diversified both its compute supply chain and its sources of capital.
Second, the principal engineering challenge in frontier AI increasingly resides not within the accelerator itself, but within the fabric connecting accelerators, racks, buildings, and campuses.
As AI operators deploy gigawatts of infrastructure across multiple geographic regions, competitive advantage increasingly depends not only on accelerator performance, but also on scale-across optics, high-density switching architectures, power availability, and the financing mechanisms capable of deploying infrastructure at unprecedented speed.
🌐 We’re tracking the latest developments in AI infrastructure. Follow our ongoing coverage at: https://convergedigest.com/category/ai-infrastructure/