
Speaking at last week’s Optica Executive Forum, Microsoft’s Yawei Yin, Senior Principal Network Developer, outlined the growing need for what he described as “scale-across” networking in AI infrastructure: distributed systems that extend beyond traditional definitions of scale-up and scale-out to connect resources across larger geographies, power domains, and operational boundaries. His core argument was that as AI training and inference systems grow, networking is no longer just a supporting component. It has become a central constraint, alongside compute, power, and reliability.
Yin began by contrasting traditional cloud data centers with the new AI-centric facilities now being built at hyperscale. In conventional cloud environments, Microsoft has deployed a mix of optical transceivers, metro interconnects, and coherent technology for long-distance transport, with 400G now serving as a mainstream building block. But in AI data centers, he said, a distinct backend network is emerging to connect GPU and XPU systems used for training and inference, while a separate front-end network continues to move user and training data close to those systems. The traffic growth driven by AI, he said, now exceeds even the extraordinary expansion seen during the pandemic, creating pressure both inside data centers and across regions.
A major theme of Yin’s talk was the need to rethink how distributed AI systems are defined. Scale-up remains the short-distance, tightly synchronized domain inside accelerator clusters, while scale-out extends those clusters more broadly. “Scale-across,” in his framing, captures the increasingly necessary step of distributing compute across campuses, metros, or even larger distances when one facility or one power domain is no longer sufficient. He said this is not optional. Moore’s Law is no longer delivering ever-larger monolithic chips, so AI systems must be built as distributed systems spanning tens of thousands or even hundreds of thousands of accelerators. In inference, he added, users also want models and private data located closer to where they live and work, creating another distributed-systems requirement.
Yin emphasized that power availability is becoming a foundational driver of this architecture. He cited the uneven geographic distribution of energy resources across the United States and said that while traditional cloud facilities typically operate in the 50 MW to 300 MW range, AI clusters are now pushing toward 1 GW to 5 GW. That makes it increasingly difficult to concentrate all training and inference capacity in one place, especially when regulatory processes for bringing power online can lag where the power itself is available. The result is a strong push toward geographically distributed AI systems—but that introduces a different set of network challenges around reliability, energy efficiency, bandwidth, latency, and jitter.
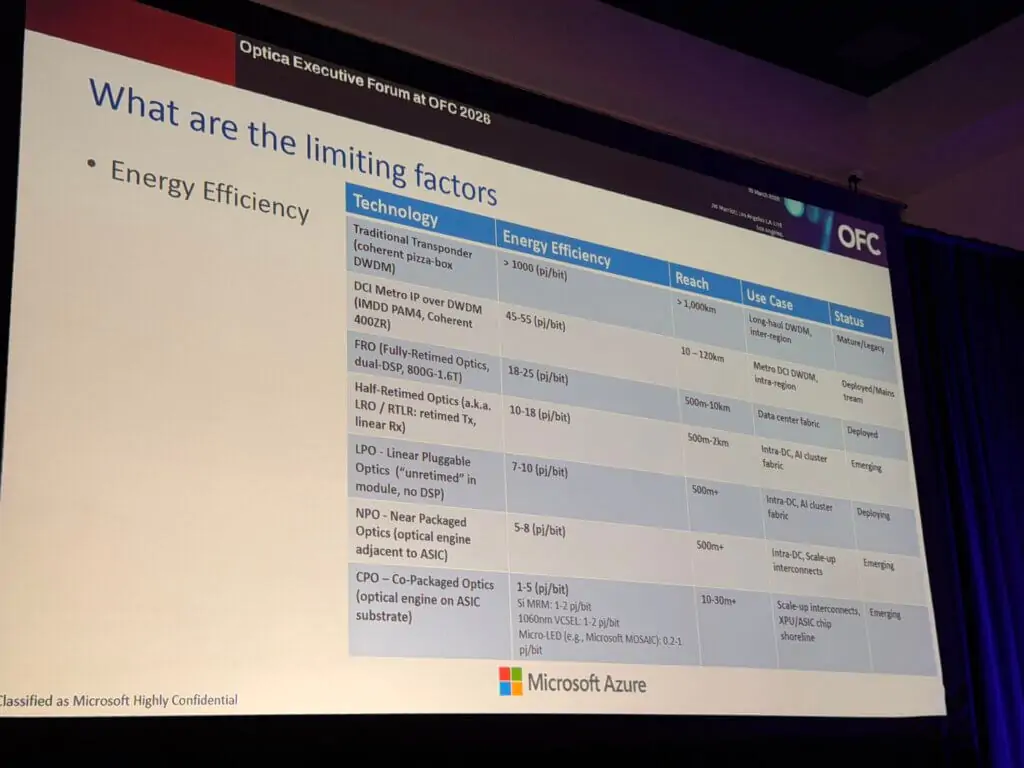
On reliability, Yin offered a vivid operational perspective, showing examples of fiber damage caused by bullets, arrows, rodents, pinches, excavators, and landslides. His point was that outside-plant fiber failures are inevitable, not exceptional, and that long-haul fiber availability falls far short of the “five nines” expectations that cloud services often target. That matters because large distributed AI jobs, especially synchronous training workloads, are much less tolerant of network disruptions than traditional distributed computing. He also highlighted the steep energy penalty of distance, noting that long-distance transport can be orders of magnitude less power-efficient than the short-reach optical and near-package interconnect technologies now being pursued inside AI systems. Latency and jitter, he said, also directly affect efficiency because synchronous collective operations force accelerators to wait, burning power while stalled.
Yin closed by surveying several technologies Microsoft sees as possible enablers for large-scale distributed AI networking. These included media-converter concepts that combine IMDD and coherent DSP elements to reduce electrical overhead and save power; co-packaged and near-package optical interface directions; hollow-core fiber, which he said offers lower latency, lower loss, and wider low-loss spectral windows than conventional fiber; optical circuit switching to extend connectivity once electrical packet switching reaches practical limits; and advanced co-packaged optics, including microring-based approaches aimed at pushing energy efficiency toward sub-pJ/bit levels. He also stressed that industry alignment through MSAs and common form factors will be essential if these technologies are to move from research and limited deployments into production infrastructure.
Key points:
- Microsoft described AI networking as extending beyond traditional scale-up and scale-out into a broader “scale-across” domain.
- Yin said AI traffic growth is now outpacing even the pandemic-era surge in cloud demand.
- Microsoft’s mainstream cloud infrastructure today is built around optical transceivers, metro links, coherent transport, and 400G-class deployments.
- AI data centers now combine a backend network for GPU/XPU synchronization with a front-end network that moves user and training data closer to accelerators.
- Yin said traditional cloud data centers typically span about 50 MW to 300 MW, while AI clusters are now pushing into the 1 GW to 5 GW range.
- He argued that distributed AI systems are necessary both because chip scaling is slowing and because power availability is geographically uneven.
- Reliability is a major obstacle for long-distance scale-across networking, especially for synchronous training jobs that are highly sensitive to link failures and jitter.
- Microsoft is evaluating technologies including hollow-core fiber, optical circuit switching, co-packaged optics, media-converter architectures, and industry MSAs to improve scale-across feasibility.
“We do need distributed systems, no matter if it’s called scale up, scale across, or scale out. But there are blockers to getting us there, and these are technologies we noticed can help us get there.”

Analysis
Yin’s presentation stood out because it framed the next stage of AI infrastructure not simply as a matter of faster optics or larger clusters, but as a systems problem shaped by energy geography, physical infrastructure risk, and the limits of synchronization across distance. That is an important shift. Much of the discussion around AI networking still centers on scale-up inside the data center and scale-out between clusters, but Microsoft is clearly thinking about a third layer—scale-across—where compute must be distributed because power, land, regulation, and resiliency increasingly dictate where capacity can actually be built.
His technology list also reflected Microsoft’s pragmatic posture. Rather than advancing a single grand answer, the talk pointed to a portfolio of approaches—hollow-core fiber for latency and spectral headroom, OCS for higher-radix connectivity, media-converter architectures for long-haul efficiency, and co-packaged optics for energy reduction inside the system. That breadth suggests hyperscalers are still in an exploratory phase on the architecture of distributed AI fabrics, but the operational problems Yin described—power concentration, fiber vulnerability, jitter sensitivity, and long-distance efficiency—are likely to shape networking roadmaps across the industry.






