A coalition of AI infrastructure leaders including OpenAI, Microsoft, NVIDIA, AMD, Intel, and Broadcom unveiled a new Ethernet transport architecture called Multipath Reliable Connection (MRC), marking a significant redesign of how large-scale AI supercomputers move data between hundreds of thousands of GPUs. Released through the Open Compute Project, MRC introduces adaptive multipath transport, multi-plane Ethernet fabrics, packet spraying, SRv6 source routing, and rapid failure recovery mechanisms intended to overcome scaling limitations in conventional RoCE-based AI networking. The architecture is already deployed in production across OpenAI’s largest frontier-model training systems, including Microsoft Fairwater and Oracle Cloud Infrastructure’s Abilene, Texas supercomputers.
The companies said MRC addresses several longstanding bottlenecks in Ethernet AI fabrics, including congestion caused by single-path traffic flows, dependence on lossless Ethernet behavior, slow convergence during network failures, and inefficiencies created by traditional “fat pipe” network designs. OpenAI described networking as one of the primary constraints in synchronous AI training environments, where millions of tightly coordinated data transfers occur during every training step and where a single delayed transfer can stall thousands of GPUs. The companies said existing RoCE implementations, originally derived from storage networking concepts, were not designed for the traffic dynamics created by frontier AI training clusters operating at hyperscale.
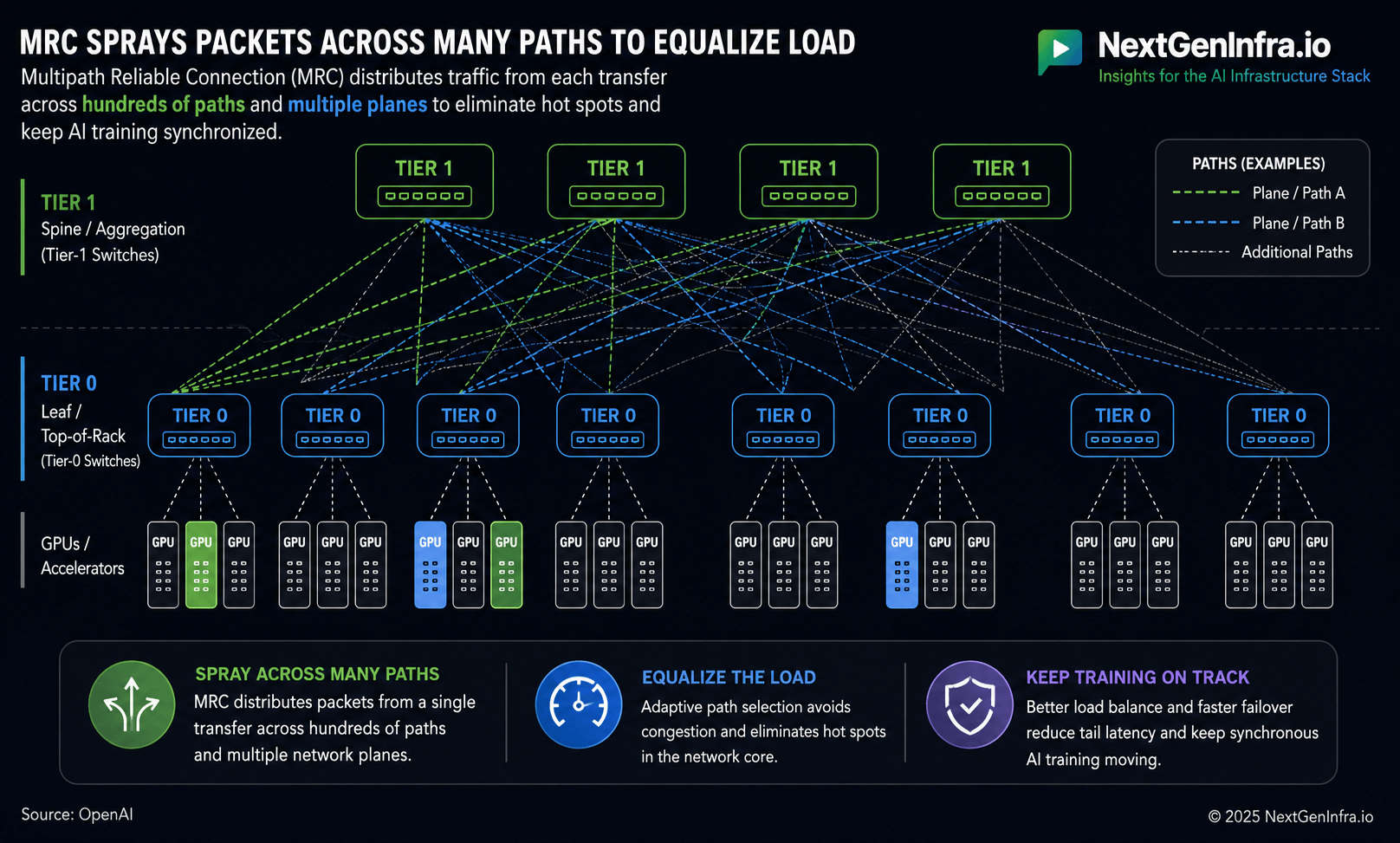
MRC fundamentally changes how traffic traverses the network. Traditional RoCE deployments typically bind a flow to a single network path to preserve packet ordering, creating hot spots when synchronized AI flows collide. MRC instead sprays packets from a single transfer across hundreds of paths and multiple physical network planes simultaneously. Packets carry their final memory destination, allowing GPUs and accelerators to place data directly into memory even when packets arrive out of order. OpenAI said this approach dramatically reduces congestion and variability in flow completion times, which are especially important for collective operations used in distributed AI training.
The protocol also introduces a multi-plane network architecture that changes the physical structure of AI fabrics. Instead of treating an 800 Gbps NIC as a single connection, MRC can split that bandwidth across multiple lower-speed links distributed over several independent Ethernet planes. For example, one 800 Gbps interface can connect through eight parallel 100 Gbps planes. OpenAI said this architecture allows a 512-port Ethernet switch to connect roughly 131,000 GPUs using only two switching tiers, reducing the need for conventional three- or four-tier AI network topologies. The flatter topology lowers power consumption, reduces latency, minimizes component count, and improves fault tolerance.
Broadcom said its Broadcom Thor Ultra NIC and Broadcom Tomahawk 5 and Broadcom Tomahawk 6 switch silicon natively support MRC functionality. Thor Ultra supports 2-, 4-, and 8-plane architectures and can distribute traffic across up to 128 paths simultaneously. Tomahawk 5 delivers 51.2 Tbps switching capacity while Tomahawk 6 scales to 102.4 Tbps. Broadcom said both switching platforms support SRv6 micro-segment routing and packet trimming, which are central mechanisms in the MRC design.
MRC also redesigns how Ethernet fabrics handle congestion and packet loss. Rather than depending on Priority Flow Control (PFC) to create a lossless network, MRC assumes packet loss can occur and handles it directly using selective acknowledgements, explicit retransmission requests, and packet trimming. When a switch experiences congestion, it can trim the payload and forward only the packet header to the destination, allowing the receiver to rapidly identify missing data and request retransmission. OpenAI said this enables recovery from failures and congestion events on microsecond timescales rather than waiting seconds for routing protocols to reconverge.
Another major architectural shift involves routing itself. Traditional Ethernet AI fabrics often rely on dynamic routing protocols such as BGP to compute alternate paths after failures occur. MRC instead uses SRv6 source routing, allowing the sender to encode the exact network path directly into the packet. Switches forward packets using static forwarding tables configured during initialization rather than continuously recalculating routes. If a path fails, MRC immediately stops using it and redistributes traffic across remaining paths without requiring network-wide routing convergence.
OpenAI said the production deployment has already demonstrated meaningful operational advantages during frontier-model training. The company reported observing multiple link flaps per minute between tier-0 and tier-1 switches without measurable impact on synchronous pretraining jobs. In another example, OpenAI rebooted four tier-1 switches during training of a frontier model supporting ChatGPT and Codex workloads without coordinating with training teams or interrupting active jobs. OpenAI also said that when links between GPUs and tier-0 switches fail, MRC recalculates paths and maintains operation with only partial bandwidth reduction rather than causing job failure.
- OpenAI, Microsoft, NVIDIA, AMD, Intel, and Broadcom collaborated on MRC over approximately two years.
- The MRC specification is now available through the Open Compute Project.
- OpenAI has already deployed MRC across its largest frontier-model training supercomputers.
- Production deployments include Microsoft Fairwater and Oracle Cloud Infrastructure’s Abilene, Texas AI supercomputer.
- MRC extends RoCE while introducing adaptive multipath transport optimized for AI workloads.
- Packets from a single transfer can be sprayed across hundreds of paths simultaneously.
- The protocol supports out-of-order packet placement directly into accelerator memory.
- Multi-plane architectures divide high-speed NIC bandwidth across multiple Ethernet planes.
- OpenAI said the design can support roughly 131,000 GPUs using only two switch tiers.
- Broadcom’s Thor Ultra NIC supports 800 Gbps connectivity and multi-plane MRC fabrics.
- Tomahawk 5 provides 51.2 Tbps switching capacity; Tomahawk 6 scales to 102.4 Tbps.
- MRC removes dependency on Priority Flow Control and lossless Ethernet behavior.
- Packet trimming allows rapid retransmission signaling during congestion events.
- SRv6 source routing eliminates dependency on dynamic routing convergence after failures.
- OpenAI said MRC can reroute around failures on microsecond timescales.
- The protocol has already been used during training of multiple OpenAI frontier models.
“At meaningful scale, that reliability and efficiency is not a nice-to-have; it is part of what makes synchronous frontier model training possible,” OpenAI said.
🌐 Analysis: MRC represents one of the most important architectural shifts in AI networking since hyperscalers began broadly adopting Ethernet for distributed GPU training. The work moves the industry beyond the idea that scaling AI infrastructure simply requires larger switches and faster optics. Instead, the transport layer itself becomes central to cluster scaling efficiency. Packet spraying, multi-plane fabrics, source routing, and adaptive congestion control collectively transform Ethernet into a more distributed, failure-tolerant system optimized for synchronized AI workloads operating across hundreds of thousands of accelerators.
🌐 Analysis: The broad industry backing behind MRC is equally significant. OpenAI, Microsoft, NVIDIA, AMD, Intel, and Broadcom collectively represent many of the largest stakeholders in AI compute infrastructure, accelerator design, switching silicon, and cloud-scale deployment. The decision to release the specification through the Open Compute Project signals an effort to establish a broadly deployable, multi-vendor Ethernet AI fabric architecture capable of competing with proprietary ecosystems such as NVIDIA NVLink and InfiniBand as AI training clusters continue scaling toward multi-hundred-thousand GPU environments.







