Google has provided one of its clearest public looks yet at how the rise of AI is reshaping the company’s network architecture—from inside the data center to its private global backbone. In a new technical blog post, Amin Vahdat describes how the infrastructure behind services such as Gemini, Veo, Search, and Cloud AI workloads increasingly depends on tightly integrated networking systems designed for massive east-west traffic, low latency, and high resilience. As model sizes grow and inference becomes more distributed, Google says networking is no longer simply connective infrastructure between compute resources. It is becoming a foundational layer of the AI system itself.
A key takeaway is the scale at which Google now treats AI infrastructure as a distributed computing platform. Training and inference workloads increasingly span multiple clusters, buildings, and even campuses, requiring Google to move enormous volumes of data across interconnected fabrics with predictable latency. Rather than concentrating compute in isolated facilities, Google describes an architecture that allows resources to be pooled across locations into what it calls a large-scale AI “hypercomputer.” This requires tight coordination between cluster networking, regional optical transport, and the company’s global WAN. According to Google, its private backbone now spans more than 7.75 million kilometers of terrestrial and subsea cable systems reaching over 200 countries and territories—forming the transport layer that links distributed AI workloads worldwide.
For network architects, the post is notable because it highlights how AI is blurring traditional boundaries between data center networking and wide-area networking. Historically, data center fabrics were optimized for short-reach east-west traffic within a building, while WAN infrastructure handled long-haul connectivity between regions. AI is changing that assumption. Large model training now generates synchronized traffic flows across thousands of accelerators, often extending beyond a single pod or campus. That means bandwidth scaling, congestion management, optical capacity planning, and traffic engineering increasingly must work as a unified system. Google frames this as an architectural convergence between switching, routing, optical transport, and software-defined control.
Google also emphasizes the role of software in orchestrating these networks. The company notes that AI workload placement increasingly depends on intelligent traffic management across multiple layers of infrastructure. Software-defined networking is used to balance traffic, isolate faults, optimize latency, and dynamically allocate capacity between competing workloads. This becomes especially important for large-scale distributed training where the slowest link in a synchronized cluster can impact overall model performance. Google’s network control plane increasingly acts as an orchestration layer between compute and transport.
The blog also underscores the importance of hardware innovation in AI networking. Google references investments in custom networking silicon, hardware acceleration, and direct memory access techniques to minimize latency and improve throughput between compute resources. This aligns with broader hyperscaler trends toward RDMA-based networking, optical scale-up fabrics, and high-radix switching architectures designed specifically for AI clusters. While the post stays at a systems level rather than detailing specific products, it reflects a broader industry shift in which networking is increasingly co-designed with accelerators, memory systems, and storage.
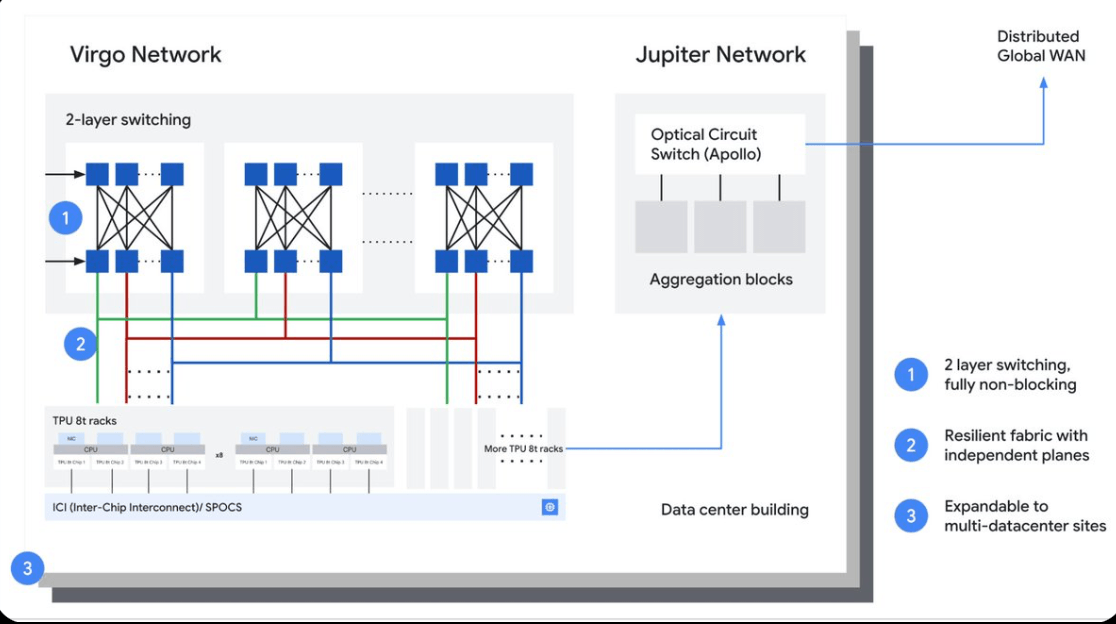
Google’s architecture closely aligns with its broader AI Hypercomputer initiative, including the Virgo scale-out fabric introduced at Cloud Next. That platform connects TPU and GPU resources at large scale while allowing workloads to be distributed across data center boundaries. Similar approaches are emerging elsewhere across the industry, including NVIDIA’s NVLink and InfiniBand-based AI fabrics, Meta’s large-scale AI cluster networks, Microsoft’s Azure AI backbone, and AWS’s work with EFA and custom optical networking. Google’s contribution to the conversation is notable because it shows how those concepts extend beyond the cluster into metro and global infrastructure.
- Google positions networking as a core architectural component of AI systems, rather than a supporting transport layer.
- AI workloads increasingly operate across multiple clusters and campuses, requiring extremely high-capacity interconnect.
- Traditional separation between data center fabric and WAN architecture is narrowing as east-west AI traffic expands geographically.
- Google relies on software-defined traffic engineering to optimize performance and workload placement across network layers.
- Network resilience remains central, with routing diversity and fault isolation built across data center, regional, and backbone infrastructure.
- The company continues investing in custom networking hardware and high-performance transport to support low-latency AI communication.
- Google’s architecture supports both internal AI workloads and external Google Cloud customers using the company’s AI Hypercomputer infrastructure.
“AI workloads are changing the scale and shape of infrastructure requirements across every layer of the network,” Google’s engineering team writes, describing an environment where data center networking and global backbone infrastructure increasingly function as a single distributed system.
Source / Credit
Google Cloud Blog — “Data center and global networks built for AI era”
By Amin Vahdat and the Google Cloud Networking team
Read the original Google Cloud blog post
🌐 Analysis: Google’s post is a strong reminder that the AI infrastructure buildout is no longer centered solely on accelerators. Networking has become one of the defining design constraints. As clusters scale toward hundreds of thousands of accelerators, the efficiency of switching, optics, routing, and workload orchestration increasingly determines system performance. The broader implication for the industry is clear: future leadership in AI infrastructure will depend not only on compute density, but on the ability to build scalable network fabrics that operate seamlessly across racks, campuses, metros, and continents.